Ich brauch erst mal 'ne Pause. Der Graphen erstell Algorithmus ist jetzt fertig, aber es ist ein
for-for-while-for-if-if-break-Konstrukt inkls. shuffle… 
Das Problem mit dot konnte ich auch umgehen, indem ich einfach neato stattdessen - denn neato kann man eine Position mitgeben.
###Edit
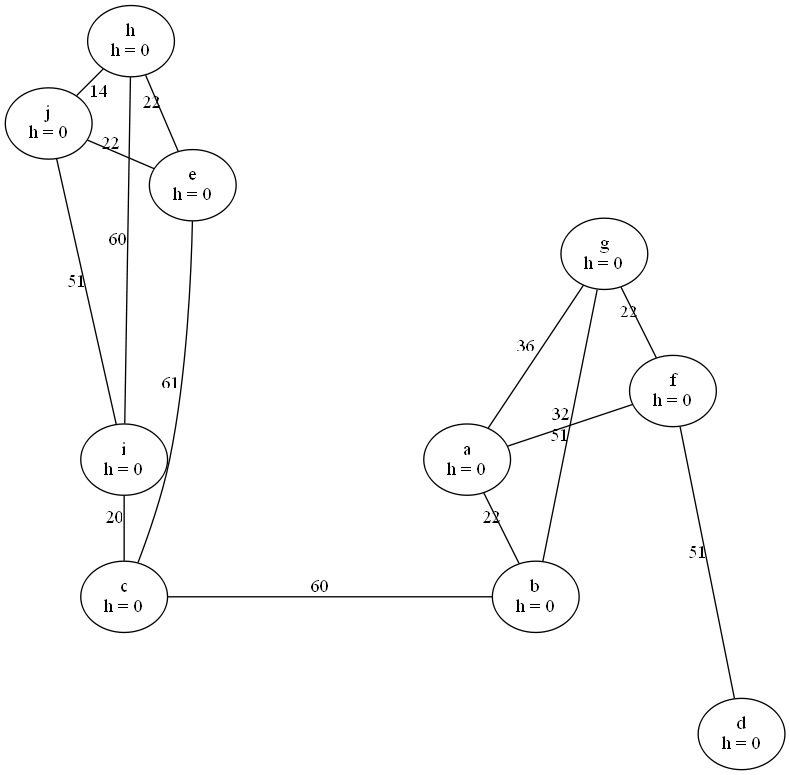
Mit neato erstelle ich (je nach Parameter) solche Graphen:
b5...
und:
b6...
graph ASternGraph {
graph [overlap = false; splines = true;]
a [label="a\nh = 0", pos="6,4!"]
j [label="j\nh = 0", pos="0,9!"]
g [label="g\nh = 0", pos="8,7!"]
c [label="c\nh = 0", pos="1,2!"]
i [label="i\nh = 0", pos="1,4!"]
e [label="e\nh = 0", pos="2,8!"]
f [label="f\nh = 0", pos="9,5!"]
h [label="h\nh = 0", pos="1,10!"]
d [label="d\nh = 0", pos="10,0!"]
b [label="b\nh = 0", pos="7,2!"]
a -- b [label="33"]
a -- f [label="61"]
a -- g [label="62"]
a -- c [label="60"]
a -- d [label="81"]
h -- j [label="22"]
e -- j [label="31"]
i -- j [label="70"]
f -- g [label="33"]
b -- g [label="69"]
c -- i [label="36"]
c -- e [label="69"]
e -- i [label="46"]
h -- i [label="66"]
e -- h [label="30"]
d -- f [label="79"]
b -- d [label="39"]
}
Frage: Schaut euch die Kante von a nach f und von g nach b an. Das Label der Kante ist schwer zu lesen. Wie kann ich neato einstellen, dass Kanten Label nicht zu dicht beieinander sind? Im Internet hab ich nur etwas zu dot und Graph gefunden.
Frage: Gesucht sei der Weg von h nach d. Wie initialisiere ich alle h’s („unsauber“).^^
Ich finde, die Diskussion ist noch nicht tot. Weitere Fragen: Wird A Stern im Navi eingesetzt? Wird A Stern in Spielen eingesetzt? Müssen zu jeder disjunkten Knotenteilmenge der Länge 2 alle hs berechnet werden, damit A Stern eingesetzt werden kann?
Ok, der ganze Schlonz, wie man den Graphen erstellt und illustriert, außen vor. Konkret hab ich zu A Stern 3 Fragen…
- Wenn man als Heuristik nicht die Luftlinie nimmt, muss man A Stern einmal für die bestmögliche Heuristik ausführen?
- Bei der Implementierung auf Wikipedia werden doppelte Knoten in der openlist vermieden. Ist es schlimm, wenn in der openlist doppelte Knote sind? Eigentlich doch nicht, total belanglos, außer vielleicht für Laufzeit.
- Was ist eigentlich mit tentative (
tentative_g) gemeint?
1 - Unsinnsthema
2 - ein korrekter Algorithmus arbeitet auf natürliche Weise korrekt, doppelte Knoten sind Unsinn,
man kann natürlich auch viel Unsinn dabei veranstalten und wohl dennoch zum Ziel kommen, Laufzeit in der Tat ein Thema,
leicht geht bei sowas aber auch viel mehr schief, nicht pauschal zu beantworten
wie schlimm das ist, ist Interpretationssache,
Beurteiler können auch bei unnötigen Kleinigkeiten 0 Punkte vergeben, Kunden 0 Euro bezahlen, usw.
3 - kreative Variablennamen sollten dir nicht fremd sein, die Bedeutung des englischen Worts ist nachschlagbar,
wenn dir Variablenname p lieber ist, dann nimm p…
der Sinn dahinter sollte vom Konzept her klar sein, es kann auf verschiedene Wege zu einem Knoten gekommen werden, verschieden lange Wege sind zu vergleichen
bei dieser Gelegenheit, vorher für ein eigenes Posting zu dämlich:
Wikipedia, Abschnitt Anwendungsgebiete:
das war schwer herauszufinden und fragenswert…
Darum geht es. Ich hab ja schon einmal ~ 0 Punkte bekommen, weil vielleicht das tiefergehende Verständnis fehlte. Das soll sich beim nächsten Mal nicht wiederholen.
[offtopic]Sonst „Kopf ab“. :([/offtopic]
Deswegen hab ich mir hier Anregungen und Antworten erhofft. Und ich finde, im Diskurs kann man mit u. a. am besten lernen…
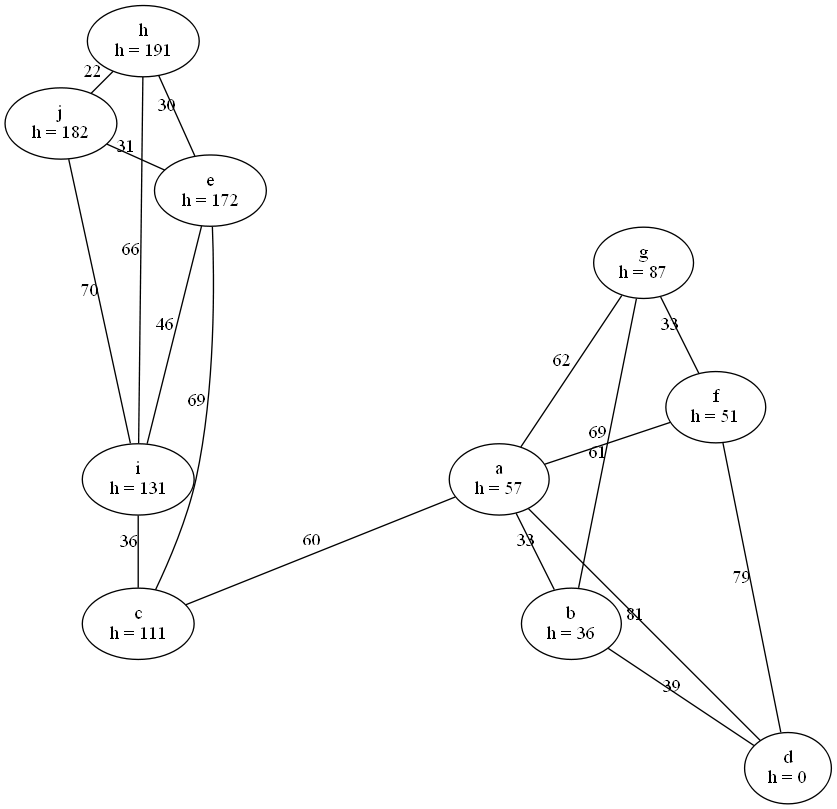
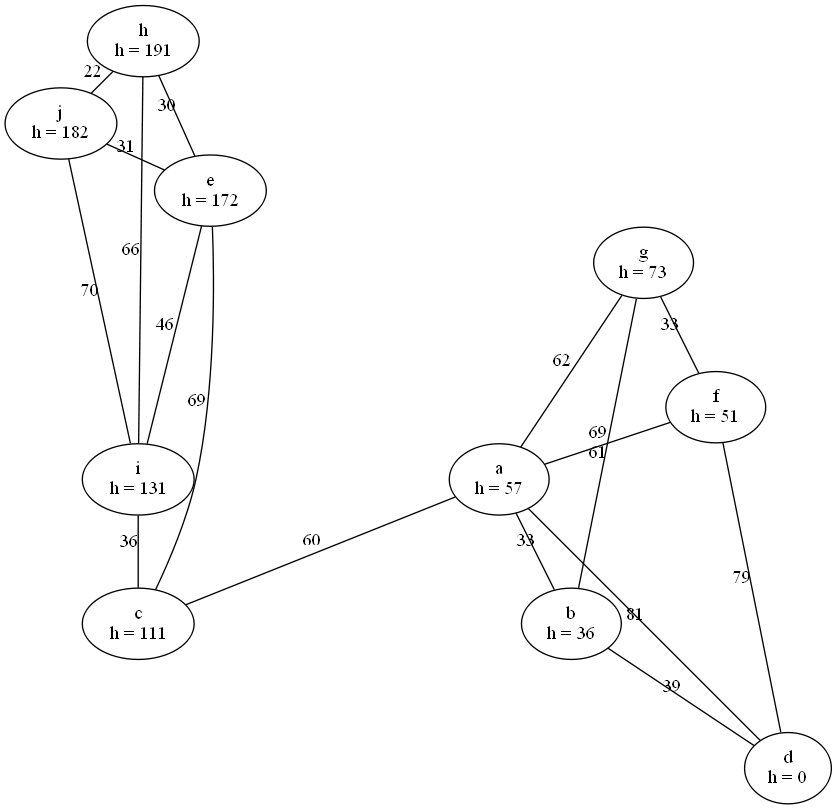
Alle h-Werte bestimmen… Orientiert hab ich mich an: A*-Algorithmus – Wikipedia . Aber ich hab den Algorithmus mit dieser Methode leicht vereinfacht. Und einmal nicht die optimale Datenstruktur verwendet:
static void setH(Knot knot) {
LinkedList<Knot> closedlist = new LinkedList<>();
PriorityQueue<Knot> openlist = new PriorityQueue<>();
openlist.add(knot);
while (!openlist.isEmpty()) {
Knot k1 = openlist.remove();
closedlist.add(k1);
for (Kant kant : k1.n) {
if (!closedlist.contains(kant.k2)) {
int newH = k1.h + (int) Math.round(dist(k1, kant.k2) * 10.0);
if (kant.k2.h == 0 || newH < kant.k2.h) {
kant.k2.h = newH;
openlist.add(kant.k2);
}
}
}
}
}
Zwischen Zeile 10 und 11 müsste eigentlich noch eine Prüfung stehen. Deswegen meine Frage: Ob er, wenn auch langsamer, trotzdem korrekt arbeitet?
Außerdem können vielleicht in der Prüfung gefragt werden:
h-Werte 1:
h-Werte 2:
Gesucht sei jeweils der Weg von h nach d. Welcher Graph stellt bessere h-Werte (Heuristik) dar, und wieso?
man kann den Algorithmus nach wie vor korrekt implementieren oder ohne jede Not Unsinn hinzufügen,
ich zumindest kann nicht abschließend beurteilen, was das für die Korrektheit bedeutet und will da auch gar nicht noch mehr Zeit drauf verwenden,
100.000 bekommen die Aufgabe A* zu implementieren und machen es auch, fertig,
warum brauchst du tausend Sonderlocken?
allein h neu zusammengesetzt zu berechnen, mal abgesehen vom fraglichen Inhalt, das kommt im Algorithmus schlicht nicht vor,
h ist für alle Knoten von Anfang bis Ende konstant, die einmalige Schätzung zum Ziel, unabhängig von allem anderen
die zweite Frage interessiert mich persönlich auch nicht, genausogut könnte gefragt werden welcher Graph sich besser als Bild im Louvre macht,
vielleicht hast du da einen ernsthaften Hintergrund, was ich bezweifle,
aber wenn dann mir zumindest nicht bekannt und ich kann es nicht weiter beantworten
Icke mal wieder… Ich verstehe noch nicht:
- Wie die Heuristik die Laufzeit verringert,
- Wie die Heuristik „einige“ Knoten von der Betrachtung ausschließt,
Mit der Frage, ob A Stern im Navi und in Spielen eingesetzt wird, sei „keine Industriespionage“ gemeint, sondern,
3. Ist A Stern „Best common/current practice“ für die Wegfindung?
[offtopic]Mit dem Aufzählungsverhalten komme ich auch noch nicht zurecht.  [/offtopic]
[/offtopic]
###Edit
Ist es so zu verstehen, dass der Zielknoten erreicht wird, ehe alle Knoten betrachtet sind (bei Dijkstra aber nicht)?
Und, wirklich nochmal die Frage, auch wenn sie infantil klingt, würd Dijkstra alle Knoten kreisförmig um den Startknoten herum untersuchen, bildlich gesprochen?
Und die Nachteile:
4. Sind nicht die Laufzeit, sondern der Speicherplatz (wie im Artikel zu lesen…), das gilt insbesondere für Dijkstra auch so?
Zu 1 und 2: Die Laufzeit wird verringert, weil eine gute Heuristik dafür sorgt, dass irrelevante Pfade nicht betrachtet werden müssen.
Wenn man z.B. einen Pfad von Hamburg nach Berlin berechnen möchte.
Dann kann eine Heuristik sagen, dass die direkte Entfernung 200 km zwischen den Städten beträgt. Fährt man dann tatsächlich auf der Autobahn, werden da dann z.B. durch Kurven etc. 250 km daraus.
AStern wird relativ schnell, den Weg mit 250 km finden. Und wenn man diesen kurzen Pfad dann einmal gefunden hat, und man nun einen Weg über Paris in betracht ziehen wollte, was ca. 1000 km von Berlin entfernt ist (Heuristik), dann sieht man gleich dass das nichts mehr werden kann, weil jede tatsächliche Route von Paris aus länger als 1000 km ist und kann die weiter Berechnung abbrechen.
Die Heuristik muss kleiner gleich der tatsächlichen Entfernung sein, aber trotzdem gut genug um irrelevante Pfade auszuschließen. Erst dann funktioniert AStern gut.
Andere Algorithmen sind teilweise leichter zu implementieren, würden aber auch versuchen Pfade über Paris zu berechnen. Dort wird also auch viel im nachhinein unnützes berechnen und haben daher höhere Komplexität und damit in vielen Szenarien eine höhere Laufzeit.
Beim Einsatz im Navi, wird man noch andere Dinge berücksichtigen müssen, da man manchmal nicht die kürzeste sondern die schnellste oder effizienteste Route haben möchte. Zudem wird man wohl auch den Suchraum im vorhinein etwas verkleinern wollen. Bei einer innereuropäischen Route wird man wohl kaum Anfangen Heuristiken für alle Punkte in Amerika und Australien zu berechnen.
UPS z.B. hat für ihre Routenberechnung einen Algorithmus verwendet, der das Linksabbiegen möglichst vermeidet, da dies in der Regel mit hohen Wartezeiten beim Abbiegen verbunden ist und dadurch Einsparungen in Millionenhöhe erwirtschaftet.