Sacht mal, vielleicht etwas blöde Frage… bei der Handschrifterkennung… erkennt man da Zeichen für Zeichen oder das ganze Wort? Und wie ist es bei Zahlen?
Es geht darum, ob das besser zu erkennen wäre:
(1.)
![]()
![]()
![]()
![]()
![]()
![]()
oder das:
(2.)
![]()
![]()
![]()
![]()
![]()
![]()
und analog bei Zahlen, das:
(3.)
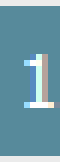
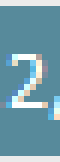
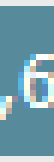
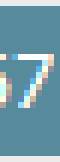
oder das:
(4.)
?
Edit Moderator: Da das offenbar aus dem WE-Thread rausgeschält wurde, ist es schwer, zu sagen, was von der folgenden Diskussion wie zu bewerten war. Hab’ mal den relevantesten Teil als einzelne Frage zusammengefasst