Ich bin aktuell gerade sehr beschäftigt mit machine learning. Unity bietet da eine nette Lib an die ich zufällig vor kurzem durch ein YouTube-Video entdeckt hab. Mein Ursprünglicher Plan war es, einen KI zu entwickeln, die Keep Your Memory besser spielt als ich.
Leider hab ich das nicht hinbekommen und mein Projekt war jetzt auch nicht gerade für KI-Training designed. Das macht es für einen Anfänger natürlich umso schwerer.
Also dachte ich: beginne ein neues Projekt, welches eine einfachere KI voraus setzt. Erstmal laaangsam anfangen.
Ich dachte auch, dass ich ein ganz gutes Anfangsprojekt habe, was ich auch für ein Spiel zu einem Game-Jam ausbauen könnte. Spielprinzip ist einfach: Straße muss überquert werden, ohne das man vom Auto getroffen wird.
Sollte recht einfach sein für den Anfang. Die KI muss wenig wissen und noch weniger Aktionen ausführen. Vergleichen wir mal die Aktionen.
Keep Your Memory
- Drehen
- Bewegen
- Schuss chargen
- Schießen
Neues Spiel
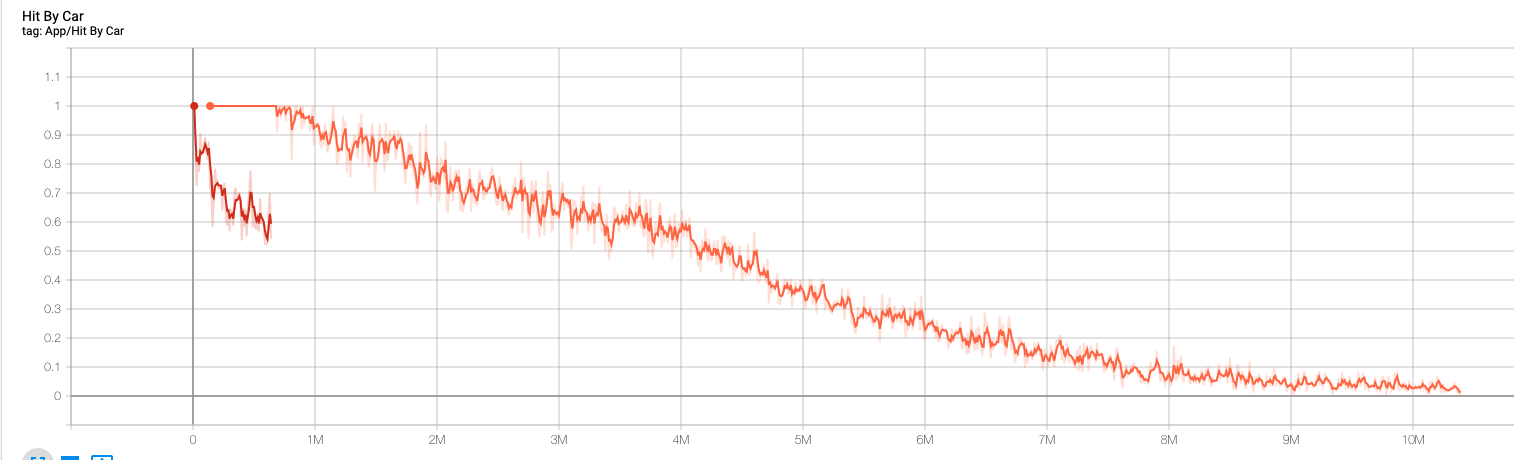
Ich wollte nicht mehr als 2 Aktionen und bin sogar nur bei 1er. Gut was  . Während ich viele Stunden schon KIs trainiert hab, haben die umgekehrt auch mich trainiert.
. Während ich viele Stunden schon KIs trainiert hab, haben die umgekehrt auch mich trainiert.
Im wesentlichen funktioniert es so. Die KI trifft in Abständen immer wieder eine Entscheidung. Ich kann jetzt mittels Rewards sagen ob die gut oder schlecht war.
- Positive Zahl = gut
- Negative Zahl = schlecht
Damit kann ich also belohnen und bestrafen. Im wesentlichen schaut mein Model derzeit so aus:
- Ziel erreichen: 1.0 (fix)
- Vom Auto getroffen werden: -1.0 (fix)
- Am leben sein: -0.001
- Nach vorne Bewegen: 0.002
- Zurück bewegen: -0.2
Kurz noch eine Erklärung was ich mit fix meine. Ein Agent (also das Teil was lernt) lernt in Episoden. Eine Episode ist vorbei wenn das Ziel erreicht wurde oder er von einem Auto getroffen wurde. Danach setzte ich den Agent auf seine Startposition zurück und beginne eine neue Episode. In dieser Zeit bekommt er von seinem Reward je nach Aktion positive oder negative Punkte. Es kann also sein, dass der Agent mit einem derzeitigen Reward von -0.5 beim Ziel ankommt. Dann addiere ich aber keine 1 sondern setze den Wert auf. Ich möchte, dass der Wert am Ende immer positiv ist - weil er könnte da auch durchaus mit -60 ankommen. Und dann ist -59 nicht so gut wie eine 1 ;-).
An der Stelle merke ich übrigens, dass ich das nur machen sollte, wenn der Wert unter 0 ist um schnelles erreichen des Ziels zu belohnen!
So. Die Zahlen die ich habe sind meine aktuellen. Die waren nicht immer so. Ich hab da ziemlich viel mit rumgespielt über die Zeit!
Generell hab ich zu Anfang haufenweise dummer Fehler gemacht. Ob ich es jetzt richtig hab, weiß ich btw nicht. Aktuell trainiere ich gerade eine (hoffentlich) vielversprechende KI.
Einer meiner ersten Fehler war das Leveldesign. Ich dachte mir: lass die KI durch ein Level rennen, wie es später auch sein könnte. Ergo: die ersten Straßen sind leichter als die am Ende. Hat nur ein paar Nachtteile:
- Warum sollte die KI erst lernen mit den einfachen Sachen klar zu kommen, wenn ich sie auch gleich gegen den härtesten Schwierigkeitsgrad trainieren lassen kann? Ich starte mit mehreren Agents parallel (50 Stück - gleiches Level). Davon kamen 1-3 bei den letzten Levels an. Somit können auch nur 3/50 meiner Agents die schweren Passagen trainieren.
- Warum überhaupt ein komplettes Level? Diese sollten sich später eh in der Anzahl der Straßen unterscheiden können. Also reicht es doch aus eine Straße auf höchster Schwierigkeit zu haben.
- Nur eine Straße haben ist dumm - zum Schluss funktioniert die KI nur wenn Autos von rechts kommen. Also hab ich eine gespiegelte Variante direkt daneben gepackt. Sodass beides trainiert wird.
Für den zweiten Punkt hab ich mehrere Tage gebraucht. Der dritte Punkt kam mir dann relativ schnell.
Ein weitere Fehler (den ich immerhin nach glaub einem Tag mit dem neuen Spiel bemerkt hatte): Meine KI weiß zu wenig! Meine KI hatte ein paar Raycasts und das wars. Irgendwann kam mir: vllt sollte sie wissen WO sie sich befindet!
Irgendwann hab ich mich gewundert, warum die KIs den Autos nicht wirklich ausweichen. Anfänglich dachte ich: die Strafe ist zu niedrig. Doch ich hab was entscheidendes gelernt: Überprüfe was deine KI sieht! Denn sie sahen die Autos nicht. Ich hatte das Auto-Gameobjekt falsch eingestellt. Die KI konnte es nicht sehen.
Als ich noch das große Level hatte, hatte ich nach jeder Straße einen Trigger aufgestellt, der die KIs belohnen soll beim durchlaufen. Negativ war: die Trigger haben wie eine Wand für die Trigger funktioniert. Meine KIs konnten schon wieder die Autos nicht erkennen.
Dann hatten meine Agents sich immer mal wieder gedreht (Phsyikalisch bedingt). Ich sende aber nur Rays nach vorne und zur Seite. D.h. nach hinten sind meine Agents Blind (aber gewollt). Was nicht gewollt ist: wenn meine KIs gedreht sind, dann schauen die nicht mehr nach vorne - sondern zur Seite oder sonst wo hin. Ergo: Sie konnten die Autos schon wieder nicht sehen (Das hatte ich aber zum Glück ziemlich Zeitgleich mit der Trigger-Wand entdeckt).
Und zu guter letzt (heute morgen rausgefunden). Nachdem ich gestern Stunden lang meine KI trainiert hatte, hatte die ein ganz seltsames Verhalten angenommen. Alle kuschelten unten rechts auf einem Fleck und ich wusste nicht warum. Ich dachte über eine erhöhte Strafe nach um Sie nach vorne zu bewegen.
Das Problem ist nur allzu menschlich! Ich würde mal sagen: die KI hatte schlicht Angst! Warum kann ich seit heute morgen kann ich es zu 100% nachvollziehen und würde mich absolut genauso verhalten. Es war nämlich folgendes:
Meine Agents kollidieren nicht miteinander. D.h. Sie verhalten sich zueinander mehr wie Geister die durch den anderen durch gehen können (sie sollen sich ja nicht gegenseitig beeinflussen). Was ich aber ich nicht eingestellt hatte, war das sie auch durcheinander durchschauen können. Somit können die nicht aneinander vorbei schauen.
Dementsprechend können die mitunter ankommende Autos nicht sehen. Die die vorbei gelaufen sind wurden also mit hoher Wahrscheinlichkeit direkt überfahren. Ich würde da auch lieber warten, bis der vor mir über die Straße gegangen ist, sodass ich sehe, was ankommt. Dummerweise hatten die dann alle noch ganz an der Seite geparkt und die Autos kommen durch eine Wand. Vllt hätte ich die Agents auch dadurch schauen lassen sollen. Aber ich wollte auch, dass sie wissen wo level-ende ist. Da wüsste ich derzeit auch nichtmal wie ich das Problem sinnvoll löse. Wobei - hab ich mehr oder weniger.
Denn dadurch, dass ich mein Trainings-level angepasst habe, gehen die Agents alle in die Mitte. Sie sehen ankommende Autos und können eine gute Möglichkeit abschätzen.
Und so schaut das level derzeit aus:
Das Thema an sich ist unglaublich spannend. Aber auch unglaublich komplex. Ihr habt jetzt nur eine sehr grobe Zusammenfassung bekommen. Denn da gibt es bei weitem noch sehr viel mehr zu beachten.