Hello, This is my second question, I want to share problems for all jcuda users.
So the question is : How to synchronize the ‚associative rule‘ of gpu to cpu’s?
Because As I heard, In computing, The floating point doesn’t warrant associative rule.
So I had simple experiment, using jcublas-dot product.
Here is the test code (I tested on Jcuda&Jcublas 11.4.1, CUDA 11.4.1, RTX-2070 super)
import jcuda.*;
import jcuda.jcublas.*;
public class JCudaTest {
public static void main(String[] args) {
int total_len = 10000;
double[] a = new double[total_len];
double[] b = new double[total_len];
for(int i = 0 ; i < total_len; i++) {
double init = i;
a[i] = init*init;
b[i] = init*init*init;
}
double c = 0.0;
for (int i = 0; i < a.length; i++) {
c += a[i] * b[i];
}
Pointer d_A = new Pointer();
Pointer d_B = new Pointer();
/* Initialize JCublas */
JCublas.cublasInit();
/* Allocate host memory for the matrices */
double h_A[] = a;
double h_B[] = b;
/* Allocate device memory for the matrices */
JCublas.cublasAlloc(h_A.length, Sizeof.DOUBLE, d_A);
JCublas.cublasAlloc(h_B.length, Sizeof.DOUBLE, d_B);
/* Initialize the device matrices with the host matrices */
JCublas.cublasSetVector(h_A.length, Sizeof.DOUBLE, Pointer.to(h_A), 1, d_A, 1);
JCublas.cublasSetVector(h_B.length, Sizeof.DOUBLE, Pointer.to(h_B), 1, d_B, 1);
/* Performs operation using JCublas */
double d = JCublas.cublasDdot(h_A.length, d_A, 1, d_B, 1);
/* Memory clean up */
JCublas.cublasFree(d_A);
JCublas.cublasFree(d_B);
/* Shutdown */
JCublas.cublasShutdown();
System.out.println(c - d);
}
}
The test result was different.
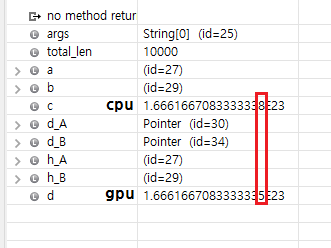
Here is different associative rule image between cpu and gpu.
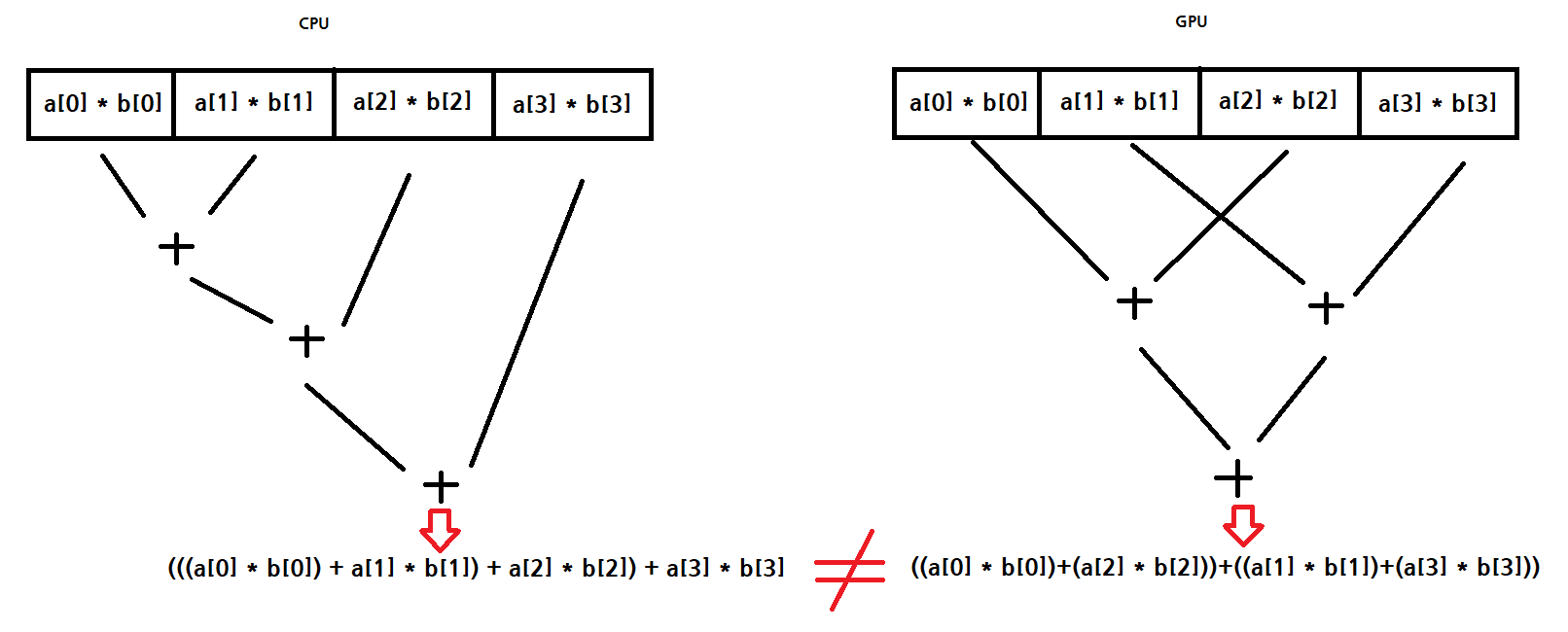
Of course, if vector length just 4, we can synchronize gpu associative rule to cpu’s using allocate more space to gpu’s vector operation.
But, if vector length will be very long(over 1000000), How to solve it?
Thank you for reading it, And if you have any solutions about this problem, please answer to me! 
