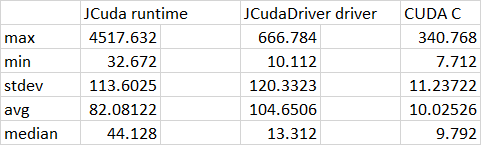
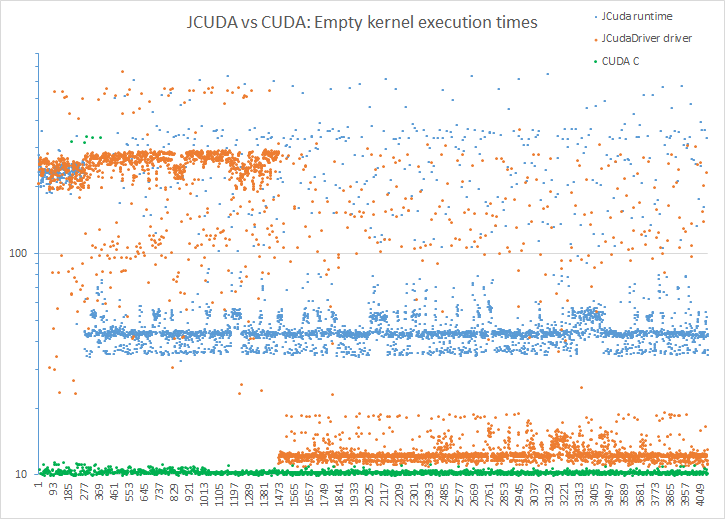
Marco, thanks for the very quick response. As you say, there will always be overhead, that is fine. What would be nice to find is the root cause of the large variance. My first suspect is GC but indeed that requires more tests. By Runtime kernel call, I really meant the KernelLauncher, sorry for the confusion.
This is the driver API code I used for the tests.
void emptyKernel(int samples) {
CUevent eventStart = new CUevent();
CUevent eventStop = new CUevent();
JCudaDriver.cuEventCreate(eventStart, CUevent_flags.CU_EVENT_DEFAULT);
JCudaDriver.cuEventCreate(eventStop, CUevent_flags.CU_EVENT_DEFAULT);
int blockSizeX = 512;
int gridSizeX = 128;
// Load the ptx file.
CUmodule module = new CUmodule();
JCudaDriver.cuModuleLoad(module, "your_kernel.ptx");
CUfunction kernel_function = new CUfunction();
JCudaDriver.cuModuleGetFunction(kernel_function, module, "empty");
// call kernel
for (int i = 0; i < samples; i++) {
JCudaDriver.cuEventRecord(eventStart, null);
cuLaunchKernel(kernel_function,
gridSizeX, 1, 1,
blockSizeX, 1, 1,
0, null, // Shared memory size and stream
null, null // Kernel- and extra parameters
);
JCudaDriver.cuEventRecord(eventStop, null);
JCudaDriver.cuEventSynchronize(eventStop);
float[] ms = new float[1];
JCudaDriver.cuEventElapsedTime(ms, eventStart, eventStop);
System.out.println(ms[0] * 1e3 + " usec");
}
}
Kernel code is just a simple kernel, please add to your .cu file and compile to .ptx:
extern "C"
__global__ void empty()
{
int x = threadIdx.x;
}
The runtime version is similar. By runtime I really meant the event call methods plus the KernelLauncher. As you see, in the code I used a parameter-passing version in my test - now replaced by call() - but that might not influence the time variance that much (I hope).
void emptyKernelRuntime(int samples) {
KernelLauncher kernelLauncher =
KernelLauncher.create("your_kernel.cu", "empty", "-arch sm_30");
kernelLauncher.setGridSize(128, 1, 1);
kernelLauncher.setBlockSize(512, 1, 1);
cudaEvent_t eventStart = new cudaEvent_t();
cudaEvent_t eventStop = new cudaEvent_t();
JCuda.cudaEventCreate(eventStart);
JCuda.cudaEventCreate(eventStop);
JCuda.cudaEventRecord(eventStart, null);
//kernelLauncher.call(dev_result, dev_coeffs, dev_buffers, position);
kernelLauncher.call();
JCuda.cudaEventRecord(eventStop, null);
JCuda.cudaEventSynchronize(eventStop);
float[] ms = new float[1];
JCuda.cudaEventElapsedTime(ms, eventStart, eventStop);
System.out.println("\t" + ms[0]*1e3 + " usec");
}
I hope this helps in reproducing the results. I will continue checking some JVM parameters effects in the meantime.
Zoltan
EDIT by Marco13: Fixed formatting