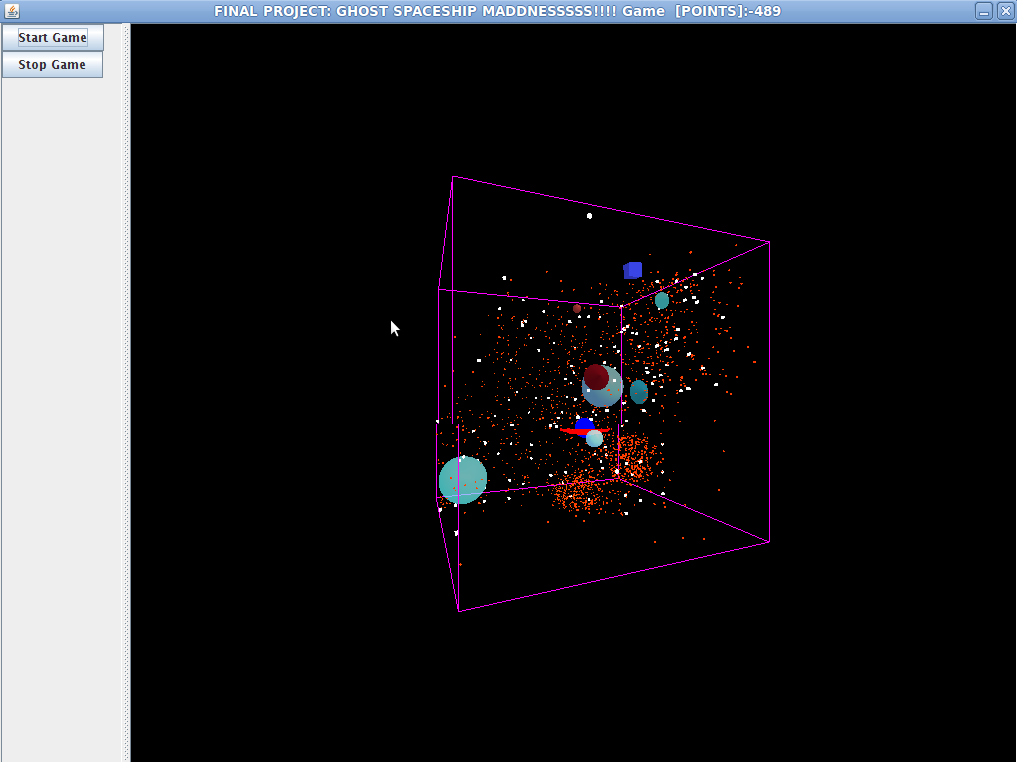
I’ve been working on some code to showcase JCUDA and parallel processing techniques. I had an old 3D game I wrote in JOGL that I altered to use JCUDA.
The particle engine I wrote now uses CUDA to calculate all particle paths (vectors) simultaneously. Each step in time calls CUDA to update all particle paths one step, all at once. Given how simple the vector calculations are I’m not surprised I’ve not seen a huge gain in performance as the overhead of transferring data to and from the GPU overshadows the simple vector math being done. I’ll throw in more complexity soon.
Here is a screen shot. Each „planet“, explosion particle (red) is placed according to GPU math. It looks better in motion. At some point I’ll post the source so people can look at a use case for JAVA-CUDA interaction.
Hey, thank you, great to see this - the video looks fancy with all those particle effects
It’s true that in many cases the memory transfer is the real bottleneck. Did you try sharing the buffers for JOGL and JCuda? Probably, people would be interested in the source code when you post it
[QUOTE=Marco13]Hey, thank you, great to see this - the video looks fancy with all those particle effects
It’s true that in many cases the memory transfer is the real bottleneck. Did you try sharing the buffers for JOGL and JCuda? Probably, people would be interested in the source code when you post it :)[/QUOTE]
Can you help me figure out how to share buffers between JOGL and JCuda? Do you have a link or source code I could read to see how this is done?
Yes, when this is done I’ll setup a Google code project for others to learn from.
// Map the vertexBufferObject for writing from CUDA.
// The basePointer will afterwards point to the
// beginning of the memory area of the VBO.
CUdeviceptr basePointer = new CUdeviceptr();
JCudaDriver.cuGLMapBufferObject(basePointer, new int[1],
vertexBufferObject);
the memory of the VBO is mapped for writing from CUDA.