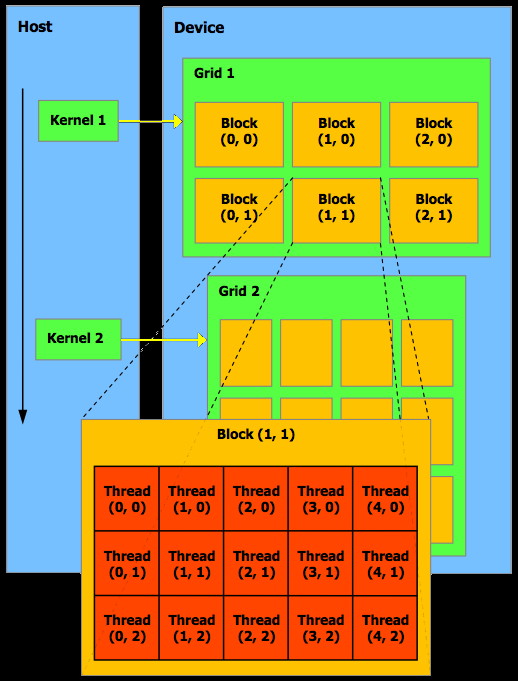
Hello
As far as I can see, the Kernel is not intended for multiplying general matrices. It is only intended for (and working with) matrices that have a size that is a multiple of the BLOCK_SIZE. So introducing a TILE_SIZE and trying to multiply 2x2 matrices will most likely not work. As the comment in the NVIDIA sample file says: For general matrix multiplication (with high performance) you should consider using the CUBLAS library. Or JCublas, in this case 
Additionally, the setup for the kernel has not been correct. In the original NVIDIA sample, the kernel is set up as
cuFuncSetBlockShape( matrixMul, BLOCK_SIZE, BLOCK_SIZE, 1 );
cuFuncSetSharedSize( matrixMul, 2*BLOCK_SIZE*BLOCK_SIZE*sizeof(float) );
cuLaunchGrid( matrixMul, WC / BLOCK_SIZE, HC / BLOCK_SIZE );
You have to specify the appropriate block size, shared memory size and grid size in the kernel launcher as well:
kernelLauncher.setBlockSize(BLOCK_SIZE, BLOCK_SIZE, 1);
kernelLauncher.setSharedMemSize(2*BLOCK_SIZE*BLOCK_SIZE*Sizeof.FLOAT);
kernelLauncher.setGridSize(WC / BLOCK_SIZE, HC / BLOCK_SIZE);
I have created an example summarizing these changes, and some minor cleanups and generalizations.
This example assumes the original „matrixMul_kernel.cu“ from the NVIDIA sample to be present. If you wish, you may replace this with your pre-compiled CUBIN file.
import static jcuda.runtime.JCuda.*;
import static jcuda.runtime.cudaMemcpyKind.*;
import java.util.*;
import jcuda.*;
import jcuda.driver.JCudaDriver;
public class KernelLauncherMatrixMult
{
private static Random random = new Random(0);
public static void main(String args[])
{
// Thread block size
final int BLOCK_SIZE = 16;
// Matrix dimensions
// (chosen as multiples of the thread block size for simplicity)
final int WA = (3 * BLOCK_SIZE); // Matrix A width
final int HA = (5 * BLOCK_SIZE); // Matrix A height
final int WB = (8 * BLOCK_SIZE); // Matrix B width
final int HB = WA; // Matrix B height
final int WC = WB; // Matrix C width
final int HC = HA; // Matrix C height
JCudaDriver.setExceptionsEnabled(true);
// Prepare the kernel
System.out.println("Preparing the KernelLauncher...");
final boolean forceRebuild = false;
KernelLauncher kernelLauncher =
KernelLauncher.create("matrixMul_kernel.cu", "matrixMul", forceRebuild);
// Create the input data
System.out.println("Creating input data...");
float matrixA[][] = createRandomFloatArray(WA, HA);
float matrixB[][] = createRandomFloatArray(WB, HB);
float matrixC[][] = new float[HC][WC];
// Allocate the device memory
Pointer deviceMatrixA = new Pointer();
cudaMalloc(deviceMatrixA, Sizeof.FLOAT * HA * WA);
Pointer deviceMatrixB = new Pointer();
cudaMalloc(deviceMatrixB, Sizeof.FLOAT * HB * WB);
Pointer deviceMatrixC = new Pointer();
cudaMalloc(deviceMatrixC, Sizeof.FLOAT * HC * WC);
// Copy memory from host to device
copyToDevice(deviceMatrixA, matrixA);
copyToDevice(deviceMatrixB, matrixB);
// Call the kernel
System.out.println("Calling the kernel...");
kernelLauncher.setBlockSize(BLOCK_SIZE, BLOCK_SIZE, 1);
kernelLauncher.setGridSize(WC / BLOCK_SIZE, HC / BLOCK_SIZE);
kernelLauncher.setSharedMemSize(2*BLOCK_SIZE*BLOCK_SIZE*Sizeof.FLOAT);
kernelLauncher.call(deviceMatrixC, deviceMatrixA, deviceMatrixB, WA, WB);
// Copy the result from the device to the host
copyFromDevice(matrixC, deviceMatrixC);
// Compute the reference solution and compare the results
float matrixCref[] = new float[WC*HC];
matrixMulHost(matrixCref, to1D(matrixA), to1D(matrixB), HA, WA, WB);
boolean passed = equalNorm1D(to1D(matrixC), matrixCref);
System.out.println(passed ? "PASSED" : "FAILED");
// Only enable this flag for small matrices!
final boolean printResults = false;
if (printResults)
{
// Print the computation and the results
System.out.println("matrixA:");
System.out.println(toString2D(matrixA));
System.out.println("matrixB:");
System.out.println(toString2D(matrixB));
System.out.println("matrixC:");
System.out.println(toString2D(matrixC));
System.out.println("matrixC ref:");
System.out.println(toString2D(matrixCref, WC));
}
// Clean up
cudaFree(deviceMatrixA);
cudaFree(deviceMatrixB);
cudaFree(deviceMatrixC);
}
/**
* Copies the data from the given array to the given device pointer.
*
* @param device The pointer to copy to
* @param array The array to copy from
*/
private static void copyToDevice(Pointer device, float array[][])
{
int rowSizeBytes = Sizeof.FLOAT * array[0].length;
for (int i = 0; i < array.length; i++)
{
Pointer deviceRow = device.withByteOffset(rowSizeBytes * i);
cudaMemcpy(deviceRow, Pointer.to(array**),
rowSizeBytes, cudaMemcpyHostToDevice);
}
}
/**
* Copies the data from the given device pointer to the given array.
*
* @param array The array to copy to
* @param device The pointer to copy from
*/
private static void copyFromDevice(float array[][], Pointer device)
{
int rowSizeBytes = Sizeof.FLOAT * array[0].length;
for (int i = 0; i < array.length; i++)
{
Pointer deviceRow = device.withByteOffset(rowSizeBytes * i);
cudaMemcpy(Pointer.to(array**), deviceRow,
rowSizeBytes, cudaMemcpyDeviceToHost);
}
}
/**
* Matrix multiplication for computing the reference
*
* @param C The result matrix
* @param A Matrix A
* @param B Matrix B
* @param hA Height of A
* @param wA Width of A
* @param wB Width of B
*/
static void matrixMulHost(float C[], float A[], float B[], int hA, int wA, int wB)
{
for (int i = 0; i < hA; i++)
{
for (int j = 0; j < wB; j++)
{
double sum = 0;
for (int k = 0; k < wA; k++)
{
double a = A[i * wA + k];
double b = B[k * wB + j];
sum += a * b;
}
C[i * wB + j] = (float)sum;
}
}
}
//=== Some utility functions =============================================
public static boolean equalNorm1D(float a[], float b[])
{
if (a.length != b.length)
{
return false;
}
float errorNorm = 0;
float refNorm = 0;
for (int i = 0; i < a.length; i++)
{
float diff = a** - b**;
errorNorm += diff * diff;
refNorm += a** * a**;
}
errorNorm = (float)Math.sqrt(errorNorm);
refNorm = (float)Math.sqrt(refNorm);
return (errorNorm / refNorm < 1e-6f);
}
private static float[][] createRandomFloatArray(int w, int h)
{
float result[][] = new float[h][w];
for (int i=0; i<h; i++)
{
for (int j=0; j<w; j++)
{
result**[j] = random.nextFloat();
}
}
return result;
}
private static float[] to1D(float array[][])
{
float result[] = new float[array.length*array[0].length];
int index = 0;
for (int i=0; i<array.length; i++)
{
for (int j=0; j<array**.length; j++)
{
result[index++] = array**[j];
}
}
return result;
}
public static String toString2D(float a[][])
{
StringBuilder sb = new StringBuilder();
for (int i=0; i<a.length; i++)
{
sb.append(toString1D(a**));
sb.append("
");
}
return sb.toString();
}
public static String toString1D(float a[])
{
StringBuilder sb = new StringBuilder();
for (int i=0; i<a.length; i++)
{
sb.append(String.format(Locale.ENGLISH, "%6.3f ", a**));
}
return sb.toString();
}
public static String toString2D(float[] a, int columns)
{
StringBuilder sb = new StringBuilder();
for (int i=0; i<a.length; i++)
{
if (i>0 && i % columns == 0)
{
sb.append("
");
}
sb.append(String.format(Locale.ENGLISH, "%6.3f ", a**));
}
return sb.toString();
}
}