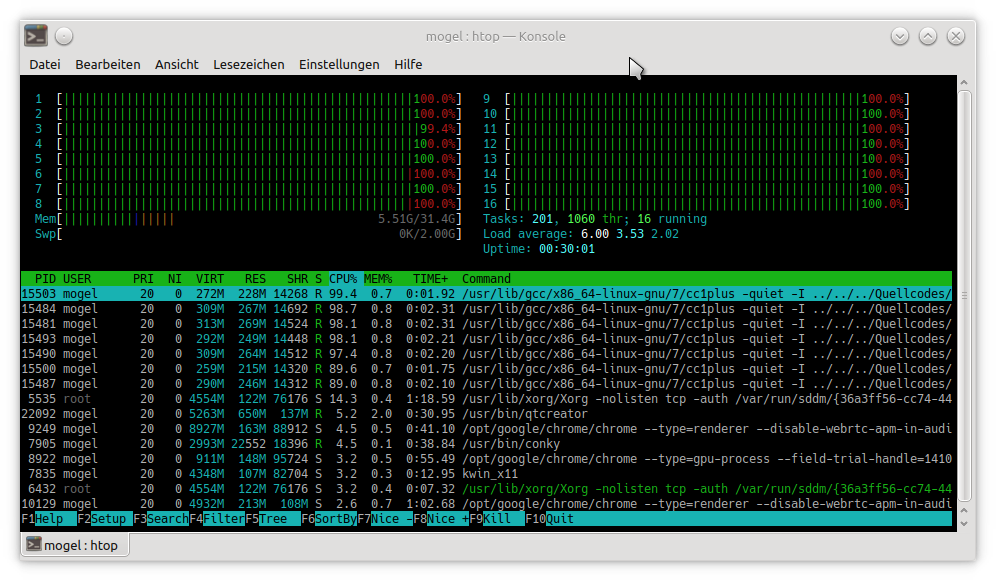
Da ich gerade mal ein Projekt von einem Kunden nicht auf dem Laptop compilere, sondern auf meinem Desktop:
rund 31000 Zeilen werden bei 16 Kernen in 37s compiliert, bei 8 Kernen werden 44s benötigt. Daraus wird eindeutig klar, das doppelte Kerne keine halbe Zeit bedeuten. (Hallo Management )
Auf dem Build-Server, beim Kunden, werden dafür über 5 Minuten benötigt. Aber da ist die Zeit ja egal
Gut, endlich ein Beleg dafür. Bisher musste man das Management immer fragen, ob es glaubte, dass 9 Frauen ein Baby innerhalb von einem Monat fertig kriegen
Dass Compilieren nicht linear skaliert, ist ja eigentlich klar, und da spielt die Anzahl der Zeilen wohl weniger eine Rolle, als eher, wie viele Dateien es sind, und wie viele davon unabhängig voneinander compiliert werden können (und wie viele header sie einbinden, die vielleicht geparst und durch den präprozessor gejagt werden müssen, obwohl sie gar nicht benötigt werden… sowas wie „Organize Imports“ ist in C++ so eine Sache…).
Mein pet peeve ist ja, auf dem Unterschied zwischen Amdahl und Gustafson rumzureiten. Damit kann man die vehement vorgebrachte Forderung, dass etwas „100 mal schneller“ werden muss (durch Parallelisierung… auf einem (damals) 4-Kerner ) filetieren, und klar machen, dass die Leute in Wirklichkeit nicht wollen, dass es „100 mal schneller“ ist, sondern sie lediglich 100 mal so viele Daten in der gleichen Zeit verarbeiten wollen.
(Äh… ja, immernoch auf einem 4-Kerner… sinnlos war die Forderung trotzdem, aber darum geht’s ja gerade nicht…)
(Mit den Details der Compilierung (vor allem auf Linux) kenn’ ich mich nicht aus. Aber es würde mich nicht wundern, wenn man (statt mit teurer Hardware) durch eins der vielen magischen gcc-flags wie -compile-only-needed-code oder -use-precompiled-headers oder -compile-faster) die Zeit einfacher reduzieren könnte…)
 )
)