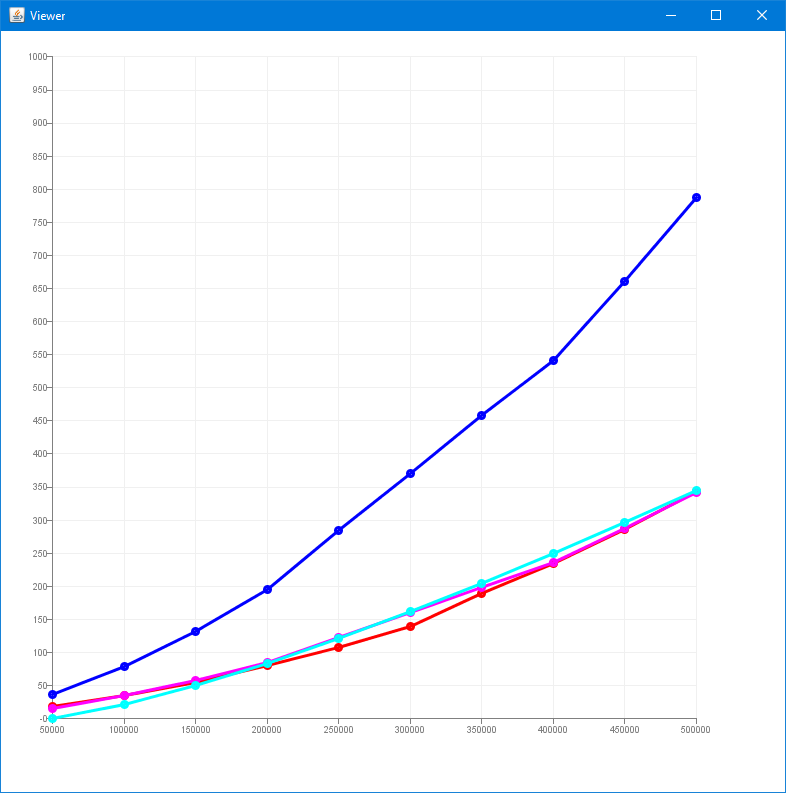
Eine SkipList und eine java.util.TreeSet haben beide für die meisten Operationen die theoretische Laufzeit von Theta(log n), wobei n die aktuelle Anzahl der gehaltenen Elemente ist. Die eigene SkipList-Implementierung (hier zu finden https://forum.byte-welt.net/t/skip-list-erstellen-in-java/22471/28?u=cyborgbeta) benötigt aber im Benchmark für die gleichen Operationen doppelt so viel Zeit wie die java.util.TreeSet.
Wieso?
Pitfall übersehen, oder liegt es in der Natur des Zufalls?
Warum ich das mache, weiß ich nicht genau. Aber OK.
Java und die JVM sind kompliziert. Einen „Benchmark“ mit Java zu machen, aus dem man Informationen ziehen kann, ist schwierig. Wenn man da was „richtig“ machen will, sollte man https://github.com/openjdk/jmh verwenden. Ist aber aufwändig. Um mit geringem Aufwand zumindest einen Hauch Information aus einem Vergleich ziehen zu können, sollte man
den Test mehrfach laufen lassen, mit verschiedenen Eingabegrößen
bei beiden Verfahren die gleichen Eingabedaten verwenden
über mehrere Läufe mitteln
black holes verwenden
vielleicht noch mit -verbose:gc starten…
tausend andere Sachen…
Aber grob angewendet auf das Beispiel:
public static void main(String[] args)
{
int blackHoleA = 0;
int blackHoleB = 0;
int runs = 5;
for (int n = 50000; n <= 500000; n += 50000)
{
Random r = null;
long beforeNs = 0;
long afterNs = 0;
r = new Random(0);
beforeNs = System.nanoTime();
for (int k = 0; k < runs; k++)
{
SkipList list = new SkipList(0.5);
for (int i = 0; i < n; i++)
{
list.add(r.nextInt(Integer.MAX_VALUE));
}
for (int i = 0; i < n; i++)
{
blackHoleA +=
list.contains(r.nextInt(Integer.MAX_VALUE)) ? 1 : 0;
}
}
afterNs = System.nanoTime();
System.out.printf(Locale.ENGLISH, "A: n=%10d: %8.3fms\n", n,
(afterNs - beforeNs) / 1e6 / runs);
r = new Random(0);
beforeNs = System.nanoTime();
for (int k = 0; k < runs; k++)
{
Set<Integer> set = new TreeSet<Integer>();
for (int i = 0; i < n; i++)
{
set.add(r.nextInt(Integer.MAX_VALUE));
}
for (int i = 0; i < n; i++)
{
blackHoleB +=
set.contains(r.nextInt(Integer.MAX_VALUE)) ? 1 : 0;
}
}
afterNs = System.nanoTime();
System.out.printf(Locale.ENGLISH, "B: n=%10d: %8.3fms\n", n,
(afterNs - beforeNs) / 1e6 / runs);
}
System.out.println(blackHoleA + ", " + blackHoleB);
}
Ja, aber das widerspricht der Kernaussage doch nicht, dass die eigene SkipList doppelt so lange braucht wie die TreeSet. Sicher, asymptotisch gesehen, verhalten sich beide gleich. Es kann/könnte aber einen Unterschied machen, ob ich für Operationen mit wahnsinnig vielen Daten 5 Sekunden oder 10 brauche.
Und das ist so… weil… ja, weil… bei jeder Operation es einen konstanten/ langsam anwachsenden Mehraufwand gibt, da es für ein Element mehrere Referenzen dorthin gibt. Eine TreeSet hat diesen Overhead nicht, dafür wäre die SkipList leichter zu implementieren, und wird deshalb auch oft verwendet.
So, jetzt aber zur eigentlichen Frage, wieso ist die Frage nach dem „Wieso?“ blöd? … Ich will da weder eine Doktorarbeit drüber schreiben noch sonst was, sondern habe einfach nur eine Aussage in den Raum gestellt und diese ist ja nun auch belegt…