Hab es mit dem OpenJDK JDK 15 zum Laufen bekommen. Zwei Probleme, einmal Lombok und einmal gibt es das import javafx.util.Pair; nicht mehr. (Zudem muss der JAVA_HOME-Path für Lombok richtig sein).
pom.xml (Lombok und <version>2.3.2</version> hinzugefügt):
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.isaac.stock</groupId>
<artifactId>StockPrediction</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<deeplearning4j.version>0.9.1</deeplearning4j.version>
<slf4j.version>1.7.21</slf4j.version>
<opencsv.version>3.9</opencsv.version>
<guava.version>23.0</guava.version>
<jfreechart.version>1.0.19</jfreechart.version>
<spark.version>2.1.0</spark.version>
</properties>
<dependencies>
<!-- DL4J and ND4J Related Dependencies -->
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-api</artifactId>
<version>${deeplearning4j.version}</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native</artifactId>
<version>${deeplearning4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>${deeplearning4j.version}</version>
</dependency>
<dependency>
<groupId>org.datavec</groupId>
<artifactId>datavec-api</artifactId>
<version>${deeplearning4j.version}</version>
</dependency>
<dependency>
<groupId>org.datavec</groupId>
<artifactId>datavec-dataframe</artifactId>
<version>${deeplearning4j.version}</version>
</dependency>
<!-- Spark Dependencies -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- OpenCSV Dependency -->
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>${opencsv.version}</version>
</dependency>
<!-- SLF4J Dependency -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- JFreeChart Dependency -->
<dependency>
<groupId>org.jfree</groupId>
<artifactId>jfreechart</artifactId>
<version>${jfreechart.version}</version>
</dependency>
<!-- Guava dependency -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<finalName>StockPrediction</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.isaac.stock.predict.StockPricePrediction</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
/StockPrediction/src/main/java/com/isaac/stock/representation/MyEntry.java hinzugefügt (an Stelle von Pair):
package com.isaac.stock.representation;
import java.util.Map;
public class MyEntry<K, V> implements Map.Entry<K, V> {
private final K key;
private V value;
public MyEntry(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public K getKey() {
return key;
}
@Override
public V getValue() {
return value;
}
@Override
public V setValue(V value) {
V old = this.value;
this.value = value;
return old;
}
}
/StockPrediction/src/main/java/com/isaac/stock/representation/StockDataSetIterator.java angepasst:
package com.isaac.stock.representation;
import com.google.common.collect.ImmutableMap;
import com.opencsv.CSVReader;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.DataSetPreProcessor;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.factory.Nd4j;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
/**
* Created by zhanghao on 26/7/17.
* Modified by zhanghao on 28/9/17.
* @author ZHANG HAO
*/
public class StockDataSetIterator implements DataSetIterator {
/** category and its index */
private final Map<PriceCategory, Integer> featureMapIndex = ImmutableMap.of(PriceCategory.OPEN, 0, PriceCategory.CLOSE, 1,
PriceCategory.LOW, 2, PriceCategory.HIGH, 3, PriceCategory.VOLUME, 4);
private final int VECTOR_SIZE = 5; // number of features for a stock data
private int miniBatchSize; // mini-batch size
private int exampleLength = 22; // default 22, say, 22 working days per month
private int predictLength = 1; // default 1, say, one day ahead prediction
/** minimal values of each feature in stock dataset */
private double[] minArray = new double[VECTOR_SIZE];
/** maximal values of each feature in stock dataset */
private double[] maxArray = new double[VECTOR_SIZE];
/** feature to be selected as a training target */
private PriceCategory category;
/** mini-batch offset */
private LinkedList<Integer> exampleStartOffsets = new LinkedList<>();
/** stock dataset for training */
private List<StockData> train;
/** adjusted stock dataset for testing */
private List<MyEntry<INDArray, INDArray>> test;
public StockDataSetIterator (String filename, String symbol, int miniBatchSize, int exampleLength, double splitRatio, PriceCategory category) {
List<StockData> stockDataList = readStockDataFromFile(filename, symbol);
this.miniBatchSize = miniBatchSize;
this.exampleLength = exampleLength;
this.category = category;
int split = (int) Math.round(stockDataList.size() * splitRatio);
train = stockDataList.subList(0, split);
test = generateTestDataSet(stockDataList.subList(split, stockDataList.size()));
initializeOffsets();
}
/** initialize the mini-batch offsets */
private void initializeOffsets () {
exampleStartOffsets.clear();
int window = exampleLength + predictLength;
for (int i = 0; i < train.size() - window; i++) { exampleStartOffsets.add(i); }
}
public List<MyEntry<INDArray, INDArray>> getTestDataSet() { return test; }
public double[] getMaxArray() { return maxArray; }
public double[] getMinArray() { return minArray; }
public double getMaxNum (PriceCategory category) { return maxArray[featureMapIndex.get(category)]; }
public double getMinNum (PriceCategory category) { return minArray[featureMapIndex.get(category)]; }
@Override
public DataSet next(int num) {
if (exampleStartOffsets.size() == 0) throw new NoSuchElementException();
int actualMiniBatchSize = Math.min(num, exampleStartOffsets.size());
INDArray input = Nd4j.create(new int[] {actualMiniBatchSize, VECTOR_SIZE, exampleLength}, 'f');
INDArray label;
if (category.equals(PriceCategory.ALL)) label = Nd4j.create(new int[] {actualMiniBatchSize, VECTOR_SIZE, exampleLength}, 'f');
else label = Nd4j.create(new int[] {actualMiniBatchSize, predictLength, exampleLength}, 'f');
for (int index = 0; index < actualMiniBatchSize; index++) {
int startIdx = exampleStartOffsets.removeFirst();
int endIdx = startIdx + exampleLength;
StockData curData = train.get(startIdx);
StockData nextData;
for (int i = startIdx; i < endIdx; i++) {
int c = i - startIdx;
input.putScalar(new int[] {index, 0, c}, (curData.getOpen() - minArray[0]) / (maxArray[0] - minArray[0]));
input.putScalar(new int[] {index, 1, c}, (curData.getClose() - minArray[1]) / (maxArray[1] - minArray[1]));
input.putScalar(new int[] {index, 2, c}, (curData.getLow() - minArray[2]) / (maxArray[2] - minArray[2]));
input.putScalar(new int[] {index, 3, c}, (curData.getHigh() - minArray[3]) / (maxArray[3] - minArray[3]));
input.putScalar(new int[] {index, 4, c}, (curData.getVolume() - minArray[4]) / (maxArray[4] - minArray[4]));
nextData = train.get(i + 1);
if (category.equals(PriceCategory.ALL)) {
label.putScalar(new int[] {index, 0, c}, (nextData.getOpen() - minArray[1]) / (maxArray[1] - minArray[1]));
label.putScalar(new int[] {index, 1, c}, (nextData.getClose() - minArray[1]) / (maxArray[1] - minArray[1]));
label.putScalar(new int[] {index, 2, c}, (nextData.getLow() - minArray[2]) / (maxArray[2] - minArray[2]));
label.putScalar(new int[] {index, 3, c}, (nextData.getHigh() - minArray[3]) / (maxArray[3] - minArray[3]));
label.putScalar(new int[] {index, 4, c}, (nextData.getVolume() - minArray[4]) / (maxArray[4] - minArray[4]));
} else {
label.putScalar(new int[]{index, 0, c}, feedLabel(nextData));
}
curData = nextData;
}
if (exampleStartOffsets.size() == 0) break;
}
return new DataSet(input, label);
}
private double feedLabel(StockData data) {
double value;
switch (category) {
case OPEN: value = (data.getOpen() - minArray[0]) / (maxArray[0] - minArray[0]); break;
case CLOSE: value = (data.getClose() - minArray[1]) / (maxArray[1] - minArray[1]); break;
case LOW: value = (data.getLow() - minArray[2]) / (maxArray[2] - minArray[2]); break;
case HIGH: value = (data.getHigh() - minArray[3]) / (maxArray[3] - minArray[3]); break;
case VOLUME: value = (data.getVolume() - minArray[4]) / (maxArray[4] - minArray[4]); break;
default: throw new NoSuchElementException();
}
return value;
}
@Override public int totalExamples() { return train.size() - exampleLength - predictLength; }
@Override public int inputColumns() { return VECTOR_SIZE; }
@Override public int totalOutcomes() {
if (this.category.equals(PriceCategory.ALL)) return VECTOR_SIZE;
else return predictLength;
}
@Override public boolean resetSupported() { return false; }
@Override public boolean asyncSupported() { return false; }
@Override public void reset() { initializeOffsets(); }
@Override public int batch() { return miniBatchSize; }
@Override public int cursor() { return totalExamples() - exampleStartOffsets.size(); }
@Override public int numExamples() { return totalExamples(); }
@Override public void setPreProcessor(DataSetPreProcessor dataSetPreProcessor) {
throw new UnsupportedOperationException("Not Implemented");
}
@Override public DataSetPreProcessor getPreProcessor() { throw new UnsupportedOperationException("Not Implemented"); }
@Override public List<String> getLabels() { throw new UnsupportedOperationException("Not Implemented"); }
@Override public boolean hasNext() { return exampleStartOffsets.size() > 0; }
@Override public DataSet next() { return next(miniBatchSize); }
private List<MyEntry<INDArray, INDArray>> generateTestDataSet (List<StockData> stockDataList) {
int window = exampleLength + predictLength;
List<MyEntry<INDArray, INDArray>> test = new ArrayList<>();
for (int i = 0; i < stockDataList.size() - window; i++) {
INDArray input = Nd4j.create(new int[] {exampleLength, VECTOR_SIZE}, 'f');
for (int j = i; j < i + exampleLength; j++) {
StockData stock = stockDataList.get(j);
input.putScalar(new int[] {j - i, 0}, (stock.getOpen() - minArray[0]) / (maxArray[0] - minArray[0]));
input.putScalar(new int[] {j - i, 1}, (stock.getClose() - minArray[1]) / (maxArray[1] - minArray[1]));
input.putScalar(new int[] {j - i, 2}, (stock.getLow() - minArray[2]) / (maxArray[2] - minArray[2]));
input.putScalar(new int[] {j - i, 3}, (stock.getHigh() - minArray[3]) / (maxArray[3] - minArray[3]));
input.putScalar(new int[] {j - i, 4}, (stock.getVolume() - minArray[4]) / (maxArray[4] - minArray[4]));
}
StockData stock = stockDataList.get(i + exampleLength);
INDArray label;
if (category.equals(PriceCategory.ALL)) {
label = Nd4j.create(new int[]{VECTOR_SIZE}, 'f'); // ordering is set as 'f', faster construct
label.putScalar(new int[] {0}, stock.getOpen());
label.putScalar(new int[] {1}, stock.getClose());
label.putScalar(new int[] {2}, stock.getLow());
label.putScalar(new int[] {3}, stock.getHigh());
label.putScalar(new int[] {4}, stock.getVolume());
} else {
label = Nd4j.create(new int[] {1}, 'f');
switch (category) {
case OPEN: label.putScalar(new int[] {0}, stock.getOpen()); break;
case CLOSE: label.putScalar(new int[] {0}, stock.getClose()); break;
case LOW: label.putScalar(new int[] {0}, stock.getLow()); break;
case HIGH: label.putScalar(new int[] {0}, stock.getHigh()); break;
case VOLUME: label.putScalar(new int[] {0}, stock.getVolume()); break;
default: throw new NoSuchElementException();
}
}
test.add(new MyEntry<>(input, label));
}
return test;
}
private List<StockData> readStockDataFromFile (String filename, String symbol) {
List<StockData> stockDataList = new ArrayList<>();
try {
for (int i = 0; i < maxArray.length; i++) { // initialize max and min arrays
maxArray[i] = Double.MIN_VALUE;
minArray[i] = Double.MAX_VALUE;
}
List<String[]> list = new CSVReader(new FileReader(filename)).readAll(); // load all elements in a list
for (String[] arr : list) {
if (!arr[1].equals(symbol)) continue;
double[] nums = new double[VECTOR_SIZE];
for (int i = 0; i < arr.length - 2; i++) {
nums[i] = Double.valueOf(arr[i + 2]);
if (nums[i] > maxArray[i]) maxArray[i] = nums[i];
if (nums[i] < minArray[i]) minArray[i] = nums[i];
}
stockDataList.add(new StockData(arr[0], arr[1], nums[0], nums[1], nums[2], nums[3], nums[4]));
}
} catch (IOException e) {
e.printStackTrace();
}
return stockDataList;
}
}
Und die Haupt-Klasse /StockPrediction/src/main/java/com/isaac/stock/predict/StockPricePrediction.java angepasst:
package com.isaac.stock.predict;
import com.isaac.stock.model.RecurrentNets;
import com.isaac.stock.representation.MyEntry;
import com.isaac.stock.representation.PriceCategory;
import com.isaac.stock.representation.StockDataSetIterator;
import com.isaac.stock.utils.PlotUtil;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.io.ClassPathResource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.IOException;
import java.util.List;
import java.util.NoSuchElementException;
/**
* Created by zhanghao on 26/7/17.
* Modified by zhanghao on 28/9/17.
* @author ZHANG HAO
*/
public class StockPricePrediction {
private static final Logger log = LoggerFactory.getLogger(StockPricePrediction.class);
private static int exampleLength = 22; // time series length, assume 22 working days per month
public static void main (String[] args) throws IOException {
String file = new ClassPathResource("prices-split-adjusted.csv").getFile().getAbsolutePath();
String symbol = "GOOG"; // stock name
int batchSize = 64; // mini-batch size
double splitRatio = 0.9; // 90% for training, 10% for testing
int epochs = 100; // training epochs
log.info("Create dataSet iterator...");
PriceCategory category = PriceCategory.CLOSE; // CLOSE: predict close price
StockDataSetIterator iterator = new StockDataSetIterator(file, symbol, batchSize, exampleLength, splitRatio, category);
log.info("Load test dataset...");
List<MyEntry<INDArray, INDArray>> test = iterator.getTestDataSet();
log.info("Build lstm networks...");
MultiLayerNetwork net = RecurrentNets.buildLstmNetworks(iterator.inputColumns(), iterator.totalOutcomes());
log.info("Training...");
for (int i = 0; i < epochs; i++) {
while (iterator.hasNext()) net.fit(iterator.next()); // fit model using mini-batch data
iterator.reset(); // reset iterator
net.rnnClearPreviousState(); // clear previous state
}
log.info("Saving model...");
File locationToSave = new File("src/main/resources/StockPriceLSTM_".concat(String.valueOf(category)).concat(".zip"));
// saveUpdater: i.e., the state for Momentum, RMSProp, Adagrad etc. Save this to train your network more in the future
ModelSerializer.writeModel(net, locationToSave, true);
log.info("Load model...");
net = ModelSerializer.restoreMultiLayerNetwork(locationToSave);
log.info("Testing...");
if (category.equals(PriceCategory.ALL)) {
INDArray max = Nd4j.create(iterator.getMaxArray());
INDArray min = Nd4j.create(iterator.getMinArray());
predictAllCategories(net, test, max, min);
} else {
double max = iterator.getMaxNum(category);
double min = iterator.getMinNum(category);
predictPriceOneAhead(net, test, max, min, category);
}
log.info("Done...");
}
/** Predict one feature of a stock one-day ahead */
private static void predictPriceOneAhead (MultiLayerNetwork net, List<MyEntry<INDArray, INDArray>> testData, double max, double min, PriceCategory category) {
double[] predicts = new double[testData.size()];
double[] actuals = new double[testData.size()];
for (int i = 0; i < testData.size(); i++) {
predicts[i] = net.rnnTimeStep(testData.get(i).getKey()).getDouble(exampleLength - 1) * (max - min) + min;
actuals[i] = testData.get(i).getValue().getDouble(0);
}
log.info("Print out Predictions and Actual Values...");
log.info("Predict,Actual");
for (int i = 0; i < predicts.length; i++) log.info(predicts[i] + "," + actuals[i]);
log.info("Plot...");
PlotUtil.plot(predicts, actuals, String.valueOf(category));
}
private static void predictPriceMultiple (MultiLayerNetwork net, List<MyEntry<INDArray, INDArray>> testData, double max, double min) {
// TODO
}
/** Predict all the features (open, close, low, high prices and volume) of a stock one-day ahead */
private static void predictAllCategories (MultiLayerNetwork net, List<MyEntry<INDArray, INDArray>> testData, INDArray max, INDArray min) {
INDArray[] predicts = new INDArray[testData.size()];
INDArray[] actuals = new INDArray[testData.size()];
for (int i = 0; i < testData.size(); i++) {
predicts[i] = net.rnnTimeStep(testData.get(i).getKey()).getRow(exampleLength - 1).mul(max.sub(min)).add(min);
actuals[i] = testData.get(i).getValue();
}
log.info("Print out Predictions and Actual Values...");
log.info("Predict\tActual");
for (int i = 0; i < predicts.length; i++) log.info(predicts[i] + "\t" + actuals[i]);
log.info("Plot...");
for (int n = 0; n < 5; n++) {
double[] pred = new double[predicts.length];
double[] actu = new double[actuals.length];
for (int i = 0; i < predicts.length; i++) {
pred[i] = predicts[i].getDouble(n);
actu[i] = actuals[i].getDouble(n);
}
String name;
switch (n) {
case 0: name = "Stock OPEN Price"; break;
case 1: name = "Stock CLOSE Price"; break;
case 2: name = "Stock LOW Price"; break;
case 3: name = "Stock HIGH Price"; break;
case 4: name = "Stock VOLUME Amount"; break;
default: throw new NoSuchElementException();
}
PlotUtil.plot(pred, actu, name);
}
}
}
Jetzt läuft es so vor sich hin und berechnet eine Prediction…
Der nächste Schritt wird sein, alle relevanten Teile der Library in mein Projekt zu integrieren (MultiLayerNetwork net = RecurrentNets.buildLstmNetworks(iterator.inputColumns(), iterator.totalOutcomes()); usw.) This will be fun. 
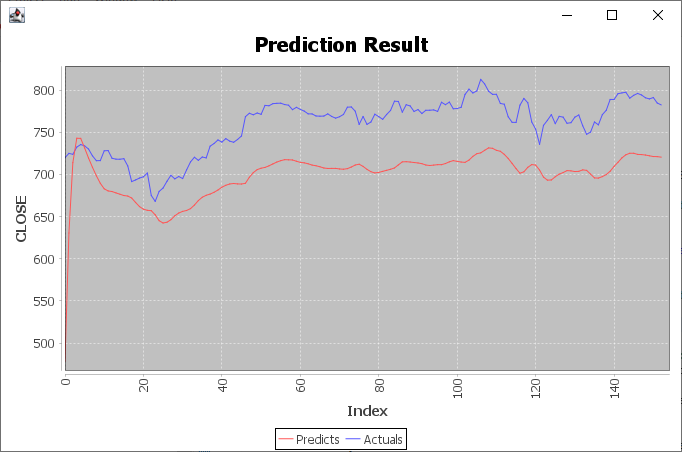
Edit: Und hier ist die Prediction, afaik, wurde das hintere Zehntel vorhergesagt:
 Weiß jemand zufällig, ob Neuroph[1][4] auch Recurrent neural networks[2], also keine Feed-forward neural networks unterstützt? Ich befürchte, nein.
Weiß jemand zufällig, ob Neuroph[1][4] auch Recurrent neural networks[2], also keine Feed-forward neural networks unterstützt? Ich befürchte, nein.  Andere (vollstädige) Implementierungen habe ich für Java nicht gefunden. Neuroph beinhaltet zwar Hopfield networks[3], aber das will ja nur 0 oder 1 haben.
Andere (vollstädige) Implementierungen habe ich für Java nicht gefunden. Neuroph beinhaltet zwar Hopfield networks[3], aber das will ja nur 0 oder 1 haben.  Thus far, schönes WE.
Thus far, schönes WE.
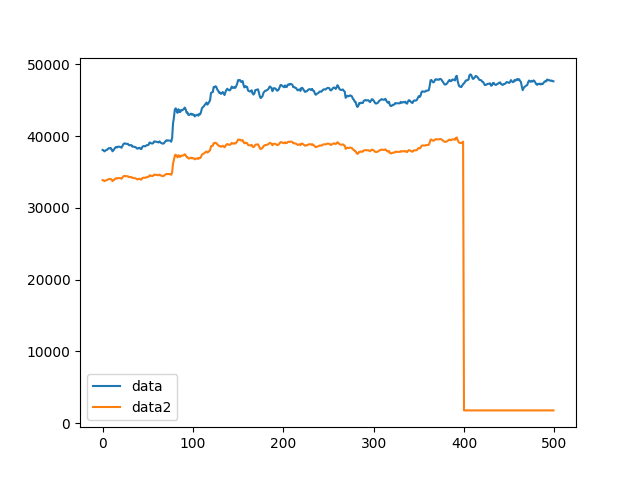
 hab nur ein paar grundlegende Fehler gemacht, aber
hab nur ein paar grundlegende Fehler gemacht, aber