Ja, ich könnte mir vorstellen, dass man da (allgemein) periodische Daten reinpackt, z.B. mit 7 oder 12 BoxPlots, in denen man (irgendwie „normalsiert“ - vielleicht einfach „als Prozent“…) die aggregierten Verläufe von 100 Wochen/Jahren reinpackt, und man dann z.B. sieht „Mittwochs geht’s runter, Donnerstags schwankt es stark“ oder so.
Einige der in diesem Artikel verlinkten Libs hatte ich schonmal gesehen, u.A. weil ich ja bei meinem (inzwischen auch privaten) Data - Libraries für Datenverarbeitung etwas gebastelt habe, was zumindest verwandt dazu ist - wenn auch nicht mit dem erklärten Ziel, „was zu machen, was so einfach ist, wie ein dataframe“.
Allgemein bietet Python zwar viel, aber das einfache Prototyping erkauft man sich halt mit anderen Dingen - und mir ist der Preis etwas zu hoch. (Subjektiv: Wackelige Versionen/Kompatibilitäten (bzw. wenig „Stabilität“ in diesem Sinne), die fehlende Typsicherheit, und wenn ich die Signaturen von einigen scipy/numpy-Funktionen sehe, rollen sich mir die Fußägel hoch).
Was ich halt immer toll finde, ist was „visuell-interaktives“. Z.B. hatte ich kürzlich meine „TimeSeries“ mit meinem Flow-based-programming-Ding (was nicht privat ist…) verwurstet, um z.B. mal schauen zu können, was passiert, wenn man bei einer „verrauschten“ Time Series das Rauschen stärker oder ein MovingAverage breiter macht, indem man einfach an den JSpinnern zieht:
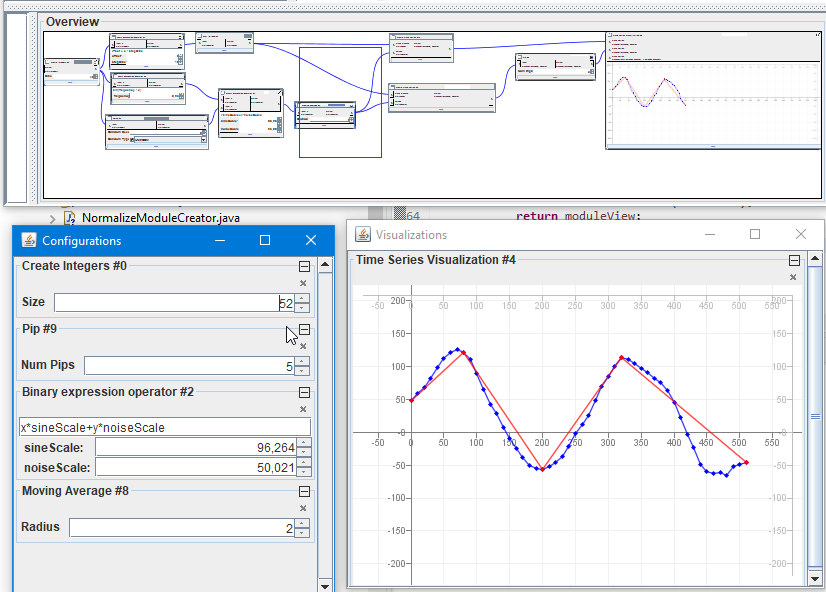
Ich finde, damit bekommt man ein viel besseres Gefühl dafür, was ein bestimmter Operator (im Datenfluss, der in der „Overview“ zu sehen ist) für Auswirkungen auf das Endergebnis hat…
Das Rote ist übrigens das Ergebnis der Berechnung von „perceptually important points“ (websuche), was anscheinend oft für „Pattern Recognition in Time Series“ verwendet wird. (Wenn man die einfach „runterimplementiert“, wie sie im Paper stehen, kann das Berechnen von 100 PIPs bei 100000 Datenpunkten schonmal 30 Sekunden dauern. Wenn man’s „richtig“ macht, sind’s dann halt nur 100 Millisekunden. D.h. das kann man auch interaktiv machen…).
Ja, das „TradingAllele“ wäre eben ein „atomarer Building Block einer Regel“. Die ganzen Begriffe/Beispiele, die du da benennst, kann ich so halt erstmal nicht einordnen. Ich hatte jetzt im wesentlichen das gegebene Beispiel verwendet. Dabei hatte ich schon ~„ein paar, wenige“ weitere Formen unterstützt, so dass die Regeln am Ende sowas sein könnten wie
CrossedUp(shortSma(12), longSma(34)) OR CrossedDown(rsi(56))
CrossedUp(rsi(23)) OR CrossedUp(shortSma(45), longSma(123)
CrossedDown(rsi(23)) OR CrossedDown(shortSma(45), longSma(123)
...
Aber die „Schwierigkeit“ (oder das, wo man die ganze Arbeit reinstecken könnte) wäre eben, dort sinnvoll andere Indikatoren zu erlauben. (Noch schwieriger wäre, nicht nur OR sondern auch AND und NOT zu erlauben, aber das kriegt man hin).
Ein Ziel könnte halt sein, dass man versucht, „gute“ Regeln zu finden, ohne zu viel Aufwand und Domänenwissen reinstecken zu müssen. Im Sinne von: „Generier’ mir mal 10 Regeln, die ‚gut‘ sind, und ich schau mir die dann in einem zweiten Schritt, als ‚Validierung‘, an, und beurteile (als Mensch) ob sie ‚sinnvoll‘ sind oder eine Mischung aus Glückstreffern und Overfitting“.
Du weißt ja sicher auch nicht, was die 100 Indicator-Implementierungen machen. Vielleicht wäre eine davon „gut“, um eine Entscheidung zu treffen? Na, lass’ halt einen Computer rausfinden, ob sie „gut“ ist. Ob sie „sinnvoll“ ist, bleibt dann immernoch dir überlassen ![]()