Nachdem die meisten kleineren1 und größeren2 Projektchen, die ich hier erwähnt habe, bisher wenig Resonanz verursacht haben, dachte ich, dass ich es mal mit einem reißerischeren Titel versuche (das nennt sich dann wohl „Click-Baiting“), um mal zu zeigen, worin einige der letzten3 Projektchen zusammenfließen.
Fließen ist auch schon das Stichwort: Es geht, im weitesten Sinne, um Flow-Based-Programming:
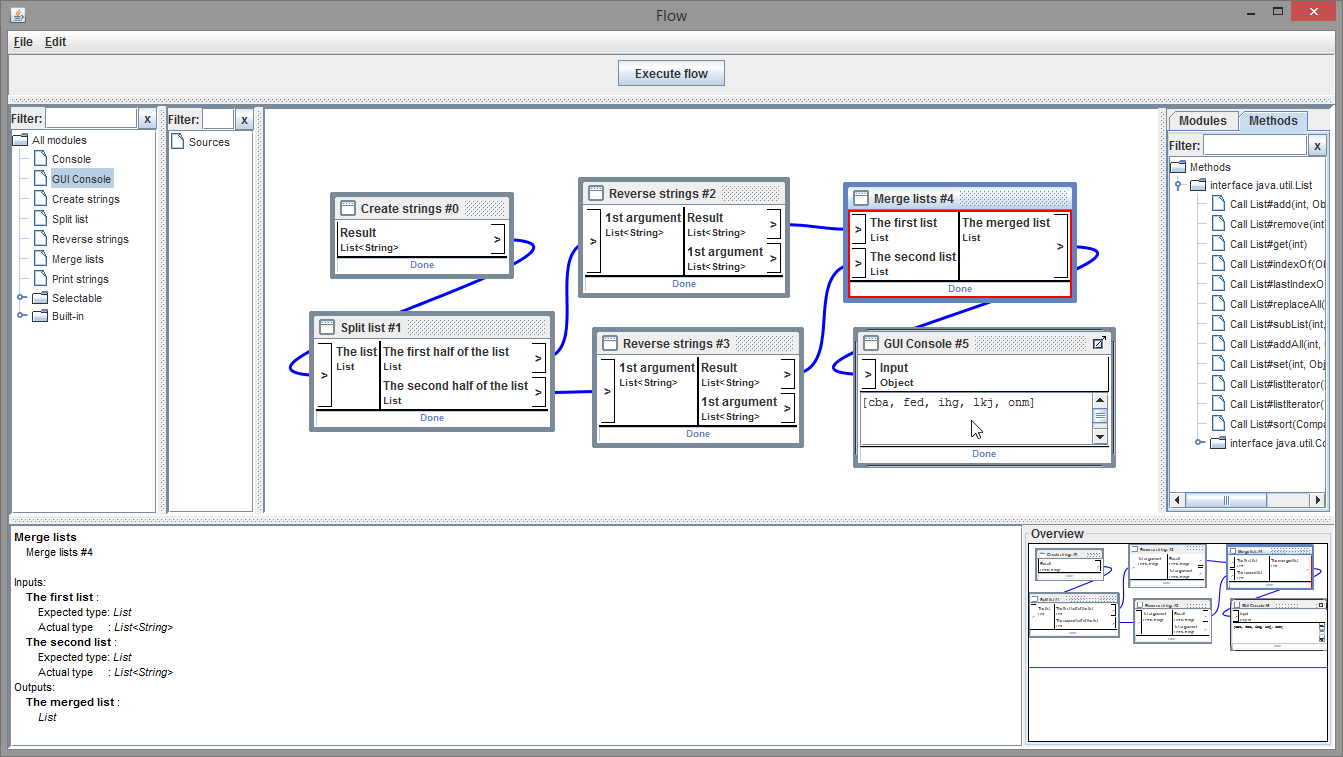
und das ganze liegt unter
Das ganze hatte ich ~2012 angefangen (inspiriert durch einen Vortrag… ich meine, auf der JAX … zum „Kanban-Flow-Pattern“ - aber damit hat es jetzt nicht mehr viel zu tun). Zwischenzeitlich war es recht weit in verschiedene Bereiche abgedriftet (Typinferenz…). Zuletzt lag es lange brach, aber jetzt habe ich mal versucht, es auf einen Stand zu bringen, wo man es sich mal ansehen kann. Es liegen vermutlich noch einige Leichen im Code, und es gibt viele mögliche Erweiterungen, aber zumindest die Demo sollte man starten und ein bißchen drin rumklicken können.
Ansonsten könnte ich vieeeel dazu schreiben, aber … das passiert wohl erstmal eher auf Englisch, um die ganzen TODOs in den READMEs zu füllen… oder als Antworten auf Fragen hier 
1:
- Viewer - ein JPanel zum Zoomen, Verschieben und Rotieren
- ViewerFunctions - Ein (sehr) einfacher Funktionsplotter
- ViewerCells - ein Viewer für Rechtecks- und Hexagon-Maps
- SwingTasks - SwingWorker on Steroids
- Common und CommonUI - nur ein paar Utility-Klassen
- Hexagon - Berechnungen auf Hexagons und Hexagon-Gittern
- JsonModelGen - Code-Generierung aus einem JSON-Schema
- Geom - Utilities für Geometrieberechnungen (in Swing/Java2D)
- Obj - Ein loader/writer für Wavefront OBJ-Dateien
- BuildOutputViewer - ein Viewer für Visual Studio build-Ausgaben
- JTreeTable - ein JTree in einer JTable
- OpenGL Fixed Function mit Shadern emulieren
2:
- Rendering - eine Java/OpenGL rendering library
- JglTF - Java libraries für glTF
- ND - Multidimensional primitive data structures
3:



 ) in einem Projekt namens „JFlow“, aber insgesamt ist „branding“ an dieser Stelle vielleicht nicht so wichtig … solange das ganze nicht „größer“ wird.
) in einem Projekt namens „JFlow“, aber insgesamt ist „branding“ an dieser Stelle vielleicht nicht so wichtig … solange das ganze nicht „größer“ wird.