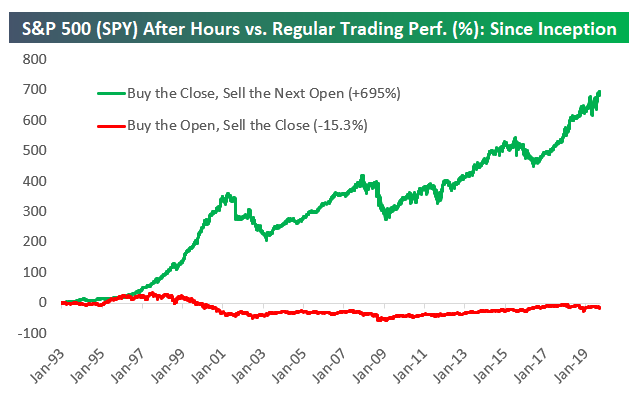
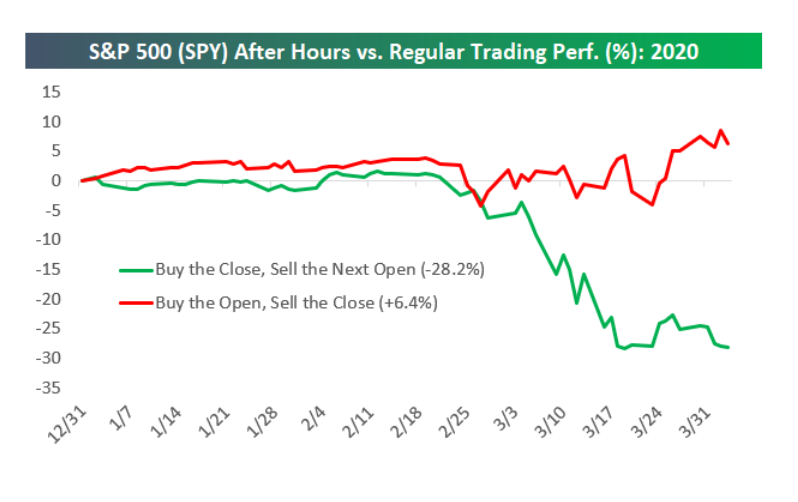
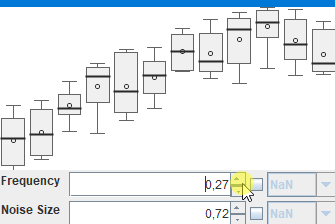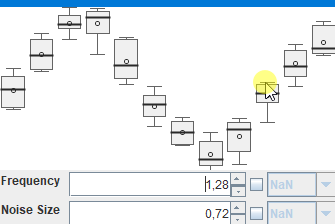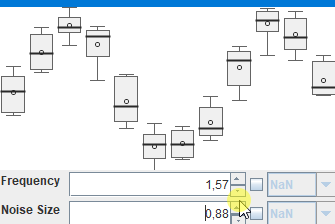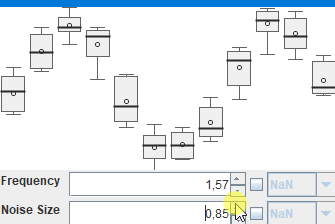
Bei sowas stelle ich mir dann immer Fragen, die im ersten Moment etwas abstrakt wirken, bei denen aber hoffentlich ein (vages) Ziel erkennbar ist: Ist das etwas, was man aus den Daten ableiten kann und will? Wenn ja: Wie müßte die Visualisierung und Interaktion gestaltet, sein, damit man leicht die richtigen/wichtigen Erkenntnisse gewinnen und Schlüsse ziehen könnte? In diesem Fall (sehr high-level - es gibt da eben viele Details, in die man in stundenlangen Meetings reinzoomen könnte) : So eine Visualisierung wie in http://javagl.de/BoxPlots.gif , wo man aber eben natürlich nicht die (den künstlich generierten Daten zugrunde liegenden) „frequency“ und „noiseSize“ interaktiv verändern kann, sondern irgendeine Kalender-Ansicht (einen „Datums/Zeitstrahl“) hat, wo man sich mit der Maus eine „Scheibe“ rausschneiden kann, die in der Visualisierung zusammengefasst wird. Diese Visualisierung wäre eben: „Zeige mir die wöchentlichen Daten, aggregiert (d.h. als 7 BoxPlots), aus den Wochen 2019/KW1 bis 2019/KW40 (und ich will den Zeitraum interaktiv verändern können, um zu sehen, wie sich damit die BoxPlots verändern)“.
Das ganze hätte dann aber natürlich noch alle möglichen Meta-Ebenen. Z.B.: „Ich will eine Visualisierung, mit der ich die in dieser Form aggregierten Daten für Zeitraum X und Zeitraum Y leicht vergleichen kann (um zu sehen, ob das eine ‚optimistische‘ oder ‚langweilige‘ Phase war). Und ich will auf einen BoxPlot draufklicken, um eine Übersicht zu bekommen, von allen Daten, die in diesem BoxPlot zusammengefasst wurden. Und ich will sehen, wo dieser Ausreißer herkommt (und dann schauen, ob an diesem Tag vielleicht Powell irgendeine Rede gehalten hat)“. („overview first, zoom+filter, details on demand, brushing+linking“, yadda yadda…)
Hmja… Ich würde nicht abstreiten, dass meine „Zurückhaltung“ in diesem Gebiet ein bißchen subjektiv-unfundiert ist (im Sinne von: „Ich kann das nicht so gut, ich mag keine ungetypten Sprachen, ich bin Java-Fan…“ etc.). Teile meiner Skepsis sind aber auch mit „Beobachtungen“ begründet (sicher nicht vollkommen objektiv, aber zumindest begründet).
Die gehen grob in diese Richtung: Leute sind keine „richtigen“ Entwickler, aber machen halt mal was mit Python. Da werden dann 10 Zeilen keras/numpy-Code von irgendeinem Blog kopiert, ein bißchen an den Parametern rumgewackelt, und ein Plot erstellt, der schick aussieht. Die Leute haben aber nicht mal den Hauch eines Ansatzes einer Ahnung, was da passiert. Weder high-level-methodisch („Ich packe mal diese Daten in ein Histogramm, weil ich das schöner finde, als einen Scatterplot“), noch low-level-methodisch („Ich verwende mal LSTM und UMAP, weil das die neuesten Verfahren sind“), noch in bezug auf etwas, was ich mit einer „Nachhaltigkeit der Ergebnisse“ zusammenfassen würde („Mit diesem Code und diesen Parametern kommen für diesen Datensatz schöne Ergebnisse raus“).
Oder flapsig: „Was ist ein ‚Senior Data Scientist‘?“ - „Jemand, der Python verwendet und älter als 25 ist“.
Ja, meine Linksammlung wird auch immer größer. Ich kann mir vorstellen, dass es zum Thema „Peak Detection“ tausende verschiedene Definitionen und Algorithmen gibt. Eine Schwierigkeit könnte eben sein, das Konzept eines „Peaks“ in einer Form zu beschreiben, die Domänen- und Datenunabhängig sinnvoll ist.
Die auf der Seite aufgelisteten sehen (beim schnellen drüberscrollen) ja ~„meistens recht ähnlich“ aus (machmal ein Punkt mehr oder weniger, ja, OK), aber schon die Frage, ob nur „Hochpunkte“ oder auch „Tiefpunkte“ als „Peaks“ gelten sollen, scheint nicht genau klar zu sein.
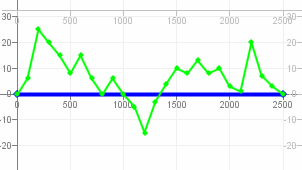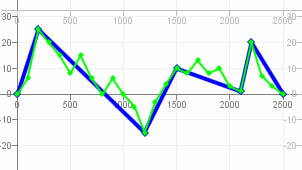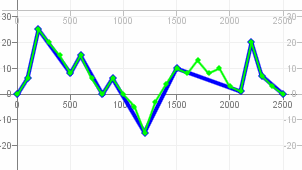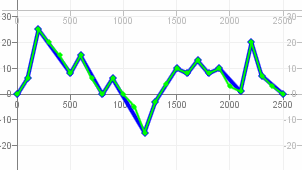
Das coole an den „Perceptually Important Points“ finde ich halt, dass man sagen kann: „Nähere mit diese Kurve mit X Punkten an, und zwar so gut wie möglich“. D.h. man mogelt sich um die Definition von „Peak“ herum, und bricht sie runter: „Ein Punkt ist ‚wichtig‘, wenn er weit von der bisherigen Annäherung weg liegt“. (Edit: Sowas wie ‚Rauschen‘ spielt dabei auch keine Rolle: Ob man 10000 „glatte“ Punkte oder 10000 „verrauschte“ Punkte auf 10 Punkte runterkondensiert, macht keinen Unterschied: Wichtig ist, was am größten ist)
Angewendet auf die Daten aus dem Artikel sieht es, wenn man die Anzahl der PIP-Punkte schrittweise erhöht, dann so aus: http://javagl.de/Pips.gif . Ich finde, dass da jeder Schritt irgendwie „sinnvoll“ aussieht (auch wenn er z.B. den „Peak“ am mittleren Punkt der W-Form (in der rechten Hälfte) erst sehr spät mit dazunimmt - es gibt eben „wichtigeres“…)
Ich kenne die Begriffe zwar nicht, aber es scheint, als wären da an vielen Stellen (vielleicht als Kapitulation vor dem Versuch, dem ganzen einen sinnvollen Namen zu geben) oft die Namen der Erfinder/Entwickler verwendet worden. Am besten noch abgekürzt. StevanovicUstalanovCriterion+ ClarkKennedyCriterion = SUCKCriterion …
Um Statistik hab’ ich auch meistens einen Bogen gemacht. Ist so un-untuitiv. In diesem Sinne bin ich mir bei der Annahme nicht sicher. (Vielleicht habe ich sie auch falsch verstanden, aber) aus „Bisher sind X und Y immer gemeinsam aufgetreten“ kann man eben nicht direkt schließen dass X und Y „immer“ gemeinsam auftreten (oder überhaupt irgendein Zusammenhang besteht). Es ist kompliziert…
Nun, in dem was ich da mal gemacht habe (eben ein schmalspur-Paper), war das ein Ziel, das eben wie üblich schön in den „Laber-Sections“ (Motivation/Discussion) rausgekehrt wurde: Wir haben Daten und ein automatisches Verfahren zum Regeln-Generieren. Aber die Regeln sind in einer (einfachen!) Sprache formuliert, so, dass ein Experte sie sich ansehen und verstehen und mit Domänenwissen validieren kann. Ich denke, dass das sinnvoll sein könnte.
Und… dass GoldmanSachs & Co Millionen in sowas stecken, und man da als einzelner kaum dagegen anstinken kann, ist klar. Aber… nun, keine „Firma“ hat eine „Idee“. Einzelne Menschen haben Ideen…
(Gut, diese Idee könnte auch sein: „Lass’ uns einen Hedgefond gründen, und eine Firma finanzieren, die eine App namens ‚RobinHood‘ rausbringt, die jeder (kostenlos!) benutzen kann, deren Nutzungsdaten wir dann aber verwenden, können, um ohne echten Aufwand unseren Profit zu vervielfachen“ - und damit kann man sich natürlich um die Notwendigkeit, etwas zu analysieren, geschickt drumrummogeln - aber die Möglichkeit hat ein einzelner natürlich nicht…)







 Ich bezahle für meine Brötchen natürlich 2000 Satoshi, und sonst nichts.
Ich bezahle für meine Brötchen natürlich 2000 Satoshi, und sonst nichts.
{kind=link}
{kind=link}