Hi,
Kurzfassung: Kann mir jemand bei der Erstellung der Binärmatrix zum Lösen eines Sudoku ähnlichen Problems mit Hilfe von Algorithm X helfen oder weiß, wo ich Fragen könnte?
Langfassung:
Wie einige wissen, erstelle ich ja gerne kleine 2d Logikspiele. Gerne auch Sudoku ähnliche Spiele. Also es gibt eine Matrix in der verschiedene Werte drin stehen und durch verschiedene Regeln kann die Matrix gelöst werden. Ob es nun Sudoku, Kakuro, Hitori etc heißt ist ja egal, alle haben das gleiche System im Hintergrund: Das Level wird nicht verschoben oder verändern, sondern nur durch Regeln gefüllt bis eine (in der Regel) eineindeutige Lösung herauskommt.
Jetzt bin ich wieder dabei so etwas zu erstellen und möchte natürlich alle Levels selber erstellen lassen. Dafür kann man ja den guten alten Brute Force Algorithmus nutzen oder seinen eigenen Algorithmus speziell für sein Problem zusammenstellen. Das ist in der Regel langsam und ineffizient. Dadurch habe ich mal geschaut, was es da schönes am Markt gibt. Und habe ich das Exact Cover Algorithmus gefunden (Exact cover - Wikipedia) und dazu die nette Variante von Knuth - Knuths Algorithm X gefunden (siehe Knuth's Algorithm X - Wikipedia ).
Nach einiger Zeit und mit Hilfe einiger netter Tutorials (Visualisierung: Exact Cover Visualizer und dazugehörige Beschreibung: GitHub - nstagman/exact_cover_sudoku: Exact Cover Sudoku Solver) habe ich ihn auch verstanden und für Sudokus selber umgesetzt. Da war ich glücklich. =)
Aber ich bekomme ihn für mein Problem gerade nicht umgesetzt.
Mein Spiel ist wie ein Sudoku. Eine Matrix, die mit Zahlen gefüllt werden muss.
Es gibt nur 3 Regeln:
- Jede Zahl darf ich jedem Bereich nur einmal vorkommen. Das bedeutet in einem „Waldbereich“, welcher 5 Felder groß ist, müssen die Zahlen von 1 bis 5.
- Im direkten Umkreis darf eine Zahl nur 1 mal vorkommen (das bedeutet wenn eine 2 in der Mitte steht, darf keine 2 in der direkten 8 Nachbarschaft (links, links oben, oben, rechts oben, rechts, rechts unten, unten, links unten) sein
- Ein Bereich (wie z.B. Wald) darf sich nicht diagonal an einen weiteren gleichen Bereich angrenzen
zur besseren Visualisierung (Ausgangslevel)

gelöstes Level mit den Regeln

Mein Problem jetzt ist, dass ich die direkte Nachbarschaft nicht in die binäre Matrix reinbekomme.
Die anderen Regeln sind kein Problem und funktionieren auch schon.
Was ist das Problem mit der direkten Nachbarschaft?
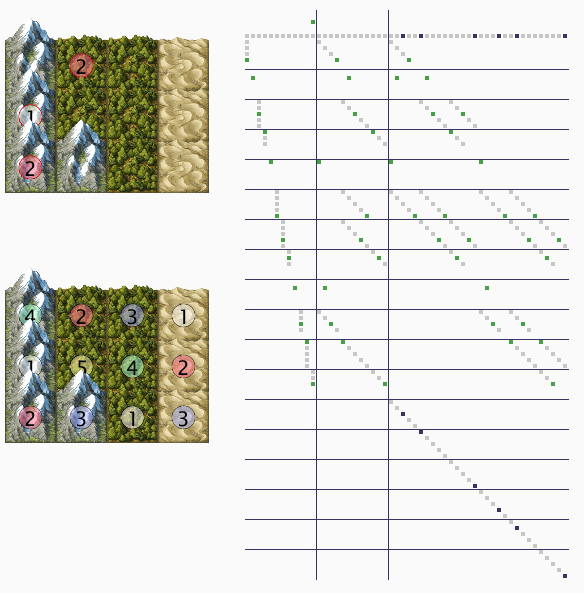
Perfektes Beispiel in der Mitte. In der Lösung steht die 4 und links und rechts davon die 3. Meine aktuelle Lösung hat das Problem, dass ich binär reinschreibe (ab Spalte 18) für Feld 0, 0 kann nur die 5 sein, also nur da die 1 aber das Feld daneben kann aktuell Werte 1 bis 5 haben also dafür die 1 rein usw … Das Problem dabei ist dass jetzt die mittlere vier mit links und rechts daneben stehenden Werten verbunden ist und somit wenn ich die drei setze, dann deselektiert er mir zwar die 3 in der Mitte, aber da die Mitte auch mit dem rechts daneben verbunden ist, tut er auch so als ob die 3 rechts mittig nicht mehr möglich ist. Das will ich aber nicht … ich weiß nur nicht wie ich es binär abbilde … kann mir da jemand helfen? Konnte ich das Problem so beschreiben, dass es überhaupt jemand verstanden hat? ![]()
Mein aktuelles binäres Array. Die Spalten 1 bis 9 repräsentieren die Möglichkeiten Zahlen reinzuschreiben, also Spalte 1 ist für Stelle oben links zuständig, da kennen wir die Zahl schon, also nur eine 1 an der 5 Stelle, da es eine fünf ist. In Spalte 2 (das Feld rechts neben der 5) ist unklar, aber kann nur die Werte 1 bis 3 beinhalten also werden sidn drei 1 zu sehen.
Die Spalten 10 bis 18 repräsentieren dass in einem Bereich nur 1 Zahl einmal vorkommen darf (also im Wasser nur die Zahlen 1 bis 3 und im Wald 1 bis 5 etc). Klappt auch wunderbar.
Nur die folgenden Spalten kriege ich nicht gelöst. =( Bitte helft mir =)